Software Buses and Data Flows with Ingescape
– Ingescape Plateforms Part 2 –
Intro 2 – Software Buses and Data Flows with Ingescape [EN|FR]
Ingescape offers a model of distributed communication between software allowing on the one hand service calls and on the other hand a circulation of information flows between software, whatever their programming language and the operating system on which they operate. It is the information flows or dataflows which constitute Ingescape’s greatest strength by finally making accessible the implementation of highly interoperable but completely decentralized heterogeneous platforms, far exceeding the State of the Art of current industrial solutions.
The information flow-based approach allows very weak coupling and very strong reusability between the software components of a system. The dynamic management of flows in Ingescape offers real-time adaptation but also over the evolutions, even substantial ones, of a given complex system.
To expose the benefits of using information flows and the qualities of Ingescape in this context, we use as comparison in this article three major technologies around software buses and information flows: MQTT, Apache Kafka and RabbitMQ. The analysis of these three technologies and their comparison with Ingescape will give the reader all the elements to understand the qualities of this type of solution in general and the advantages of Ingescape compared to technologies that are often more complex and paradoxically less efficient or less versatile. If you haven’t already, we recommend first reading Ingescape Platforms – Part 1 – Distributed Architectures and the Cloud with Ingescape.
MQTT – topics and brokers
MQTT is a widely used communication solution in the world of the Internet of Things. Imposing a very low additional cost compared to the raw data to be transported, it is very popular in a field where each byte is counted to preserve the autonomy of equipment and save money for dat volume-based economical models.
MQTT is the archetype of centralized communication buses: a broker serves as a communication relay between producers of information and consumers of this same information. Multiple producers and consumers can relate to the broker, allowing a more flexible relationship between them than traditional client/server approaches. Communication between producers and consumers is done around the notion of topic. A topic can be seen as a shared and open communication channel. Consumers subscribe to topics that interest them and the producers publish information on topics. Any consumer which subscribes to a given topic then receives the published information on this topic. It’s a simple principle that is similar to that of messaging and discussion tools between people, which has been popular for a long time.
In the illustration below, a vehicle – producer – uses MQTT to transmit its speed. Speed information is relayed via a topic named “speed”. A mobile phone and a data server – consumers – subscribe to this topic and receive the information through the broker as publications are achieved by the producer.
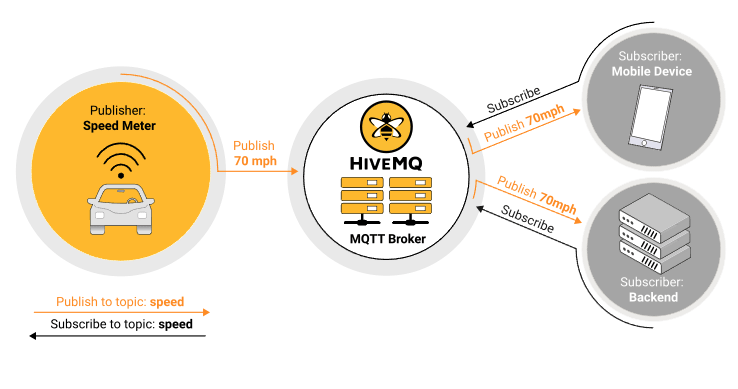
In this type of solution, the broker is a central server used both to manage the connections of producers and consumers and to transmit information between them. It is a node on a system whose failure blocks all the consumers and producers who use it and which can constitute a bottleneck in terms of bandwidth. The obligatory passage of information by the broker also induces unavoidable additional latency.
Ingescape is a brokerless solution
The previous paragraph highlights the classically recognized disadvantages of software buses based on brokers. Ingescape makes the different choice to offer a completely decentralized system in which producers and consumers – which we indistinctly call agents – constitute a meshed network. In an Ingescape platform, the agents know each other thanks to the mesh created automatically.
In the majority of cases, the meshing is carried out using a self-discovery system between agents. In the rare cases where this mechanism cannot be used, there are Ingescape brokers whose use is limited to linking agents, which corresponds to the concrete definition of a broker which shouldn’t bear the brunt of transactions between other players. With Ingescape, the data then passes directly from peer to peer, which differentiates the Ingescape brokers of brokers in the sense of MQTT, Kafka or RabbitMQ, closer to traditional servers.
This is a fundamental aspect of Ingescape: setting up an Ingescape platform made up of multiple agents only requires the agents themselves without additional infrastructure or administration, whether on the same computer or on the same network. This flexibility and ease of implementation make Ingescape completely suitable for use in prototyping contexts on temporary environments, as well as for rich and robust industrial platforms.
Each agent being both a producer and a consumer, we model the agents in the form of “boxes” independent of each other, exposing “inputs” and “outputs”. Inputs from one agent can be linked – we call it mapping – to outputs from other agents. An agent output can be linked to an indeterminate number of other agent inputs and an agent input can be fed by an indeterminate number of other agent outputs.
With Ingescape, the example given to illustrate MQTT looks like this:
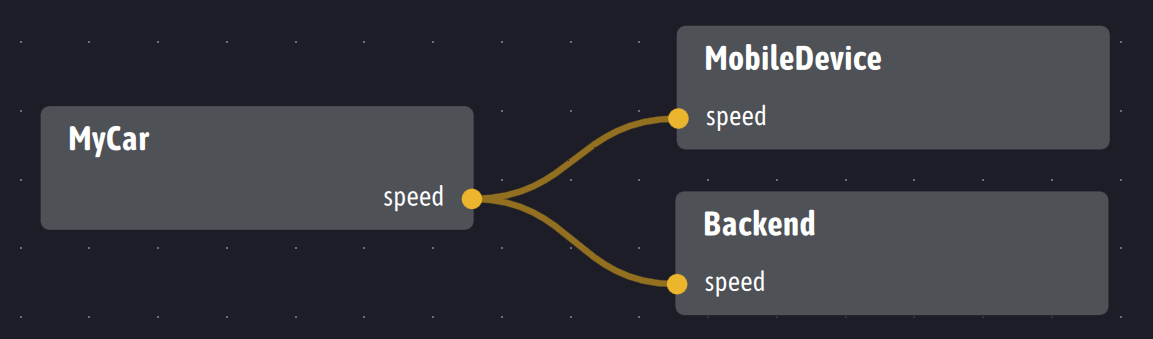
In a completely decentralized system, relations between inputs and outputs advantageously replace topics using peer-to-peer communications. Systems using Ingescape materialize in the form of software agents which, depending on their role, are able to receive and send information, named and typed, with a resulting system which is a composition of agents and flows of information between them. Under this angle, an Ingescape platform is a set of agents exposing inputs and outputs linked together by a mappings.
An indirect – yet major – benefit of using Ingescape is the ability to view and monitor an entire system and not just the central points called brokers in other technologies: the presence of agents, the exchanged information through mappings (as well as the requests/responses via the services which are not the subject of this article) are observable in time -real using the Ingescape Circle tool suite. Moreover, each agent being characterized as both consumer and producer, it is the agents who carry the topology of a system, without having to introduce the intermediaries that are the brokers, which usually harm both the representation of information flows and its fluid circulation.
The capabilities of Ingescape, for local networks connected to remote platforms or clients, exposed in the article Ingescape Platforms – Part 1 – Distributed Architectures and the Cloud with Ingescape, expose the limits for solutions based on brokers and topics such as MQTT and, in fact, position them for very constrained environments where even a signal of life must be avoided for save bandwidth. As soon as a TCP or UDP connection is possible, Ingescape immediately brings more flexibility and a better capacity for supervision and control.
Interoperability between MQTT and Ingescape
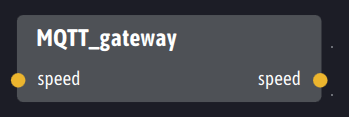
Ingescape offers a generic gateway agent dedicated to interoperability with MQTT. This gateway connects to an MQTT broker and dynamically exposes its topics as {input, output} sets. If the MQTT broker receives a post on a topic, the Ingescape MQTT gateway in turn relays this post on its corresponding output. Symmetrically, if an Ingescape agent wants to publish on an MQTT topic, it writes on the corresponding input of the gateway which then takes care of relaying it to the matching MQTT topic.
For our “speed” example, here is the form that the Ingescape MQTT gateway takes:
The topics or channels with Ingescape
First introduced for communication needs in its meshed agents network, Ingescape offers communication capability through topics – or channels -, which are the other common name for this paradigm. In this paradigm, any agent can post to channels and any other agent can subscribe to channels of their choice. and thus receive the messages that are published there. This mechanism is used to maintain internal consistency between agents. It remains accessible to users who wish to use it and who can use their own channels. Unlike MQTT and other solutions of the same family, this communication by channels proposed by Ingescape still do not require a broker and remain completely decentralized.
Apache Kafka – massive flows, history of exchanges, scalability of brokers and consumers
Always around the concepts of producer, consumer, topics and brokers, Apache Kafka is the gold standard for massive data exchange on world-class geographic and hardware scales.
Apache Kafka is distinguished by two major elements:
- Kafka brokers have a memory and historization capability that allows consumers to access the past values of a given topic,
- Kafka offers advanced topological management of brokers and consumers, allowing redundancy and partitioning brokers in clusters, as well as a breakdown of data to consumers who also know how to take advantage of partitions.
Here is the general pattern of communications in Apache Kafka:
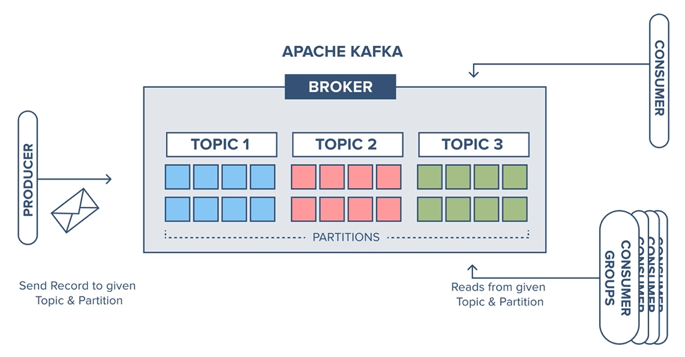
We find producers, consumers, brokers and topics. With Kafka, the topics can be segmented into partitions, ie into disjoint groups. These partitions can be established according to a specific “key” or “keys” such as the original producer or the data – structured in the form of keys/values – contained in the messages. Partitions can exploit the presence of a key or the value associated with a given key to insert a new entry – called a record into a specific partition of a topic.
Topics are stacks of data. An entry in a topic is called a record. The records are stored and ordered in each topic or each partition of topic. Consumers therefore have the possibility of accessing the history of records of a topic in order to be able to resume their processing at from a certain date or from the last value they have obtained. By default, it is also possible to recover only the last record inserted but also all the stored records , which can represent a very important volume of data. This historization mechanism requires Kafka messages, i.e. records, to include additional information about their indexing so that consumers can identify their rank or their date and proceed to requests to brokers to recover records newer or older than their benchmark. Similarly, the reception of a message requires processing concerning its index and induces heavier messages on the network than MQTT for example.
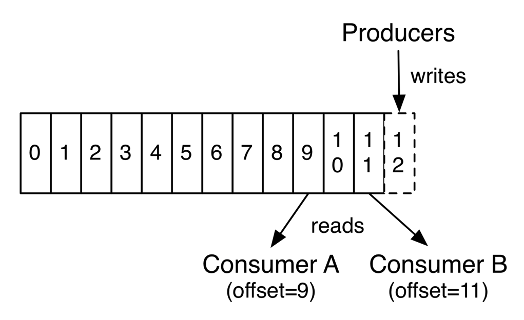
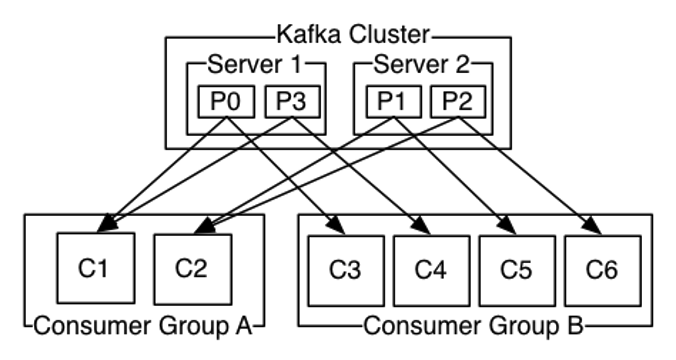
To distribute the storage and processing load, brokers can be divided into clusters, i.e. a set of servers that can share the different partitions of a given topic. The synchronization between servers so that all the data of a topic is save, is carried out asynchronously and in the background by the Kafka infrastructure. In addition, consumers can be associated in groups and share, within a group, the different partitions. Depending on the number of consumers in a group and the number of partitions, Kafka manages the distribution of load and data to consumers in each group, with possibilities for hot redundancy involving “standby” consumers.
Apache Kafka offers advanced and original solutions for the durability of information, the distributed management of very large volumes of data between servers and towards consumers. Load management for consumers is also at the heart of RabbitMQ technology. We will therefore come back to this subject later in this article to compare Kafka and RabbitMQ to Ingescape. We will first compare here Apache Kafka and Ingescape in terms of data persistence and load management on brokers/servers.
Historization of information and scalability of data flows with Ingescape
The counterpart of Apache Kafka’s strong distribution and historization capacity is the high complexity and heaviness of its implementation and the administration of the associated platforms. As such, Kafka is rather used by large companies with the ability to mobilize one or more maintenance teams and significant hardware infrastructures hosting brokers. Finally, the producer/broker/consumer pattern makes Kafka inefficient for systems that need to handle very large amounts of information but with very low latency and very high local throughput. Kafka makes more sense for systems involving geographically distant networks.
In order for Ingescape to be able to offer services equivalent to those of Kafka on the historization and scalability of brokers, here are the points to be addressed:
- Translation in Ingescape of the Kafka architecture of the diagram above
- Distribution of producer streams between multiple servers in a cluster,
- Short-term memory and historization of topics, i.e. data communicated by producers,
- Breakdown of data relayed by brokers to consumers.
1- Reproduction of the Kafka architecture of the diagram above with Ingescape concepts
Let’s first consider whether or not the introduction of a broker is necessary in Ingescape. If we take the Kafka example above with four partitions numbered P0 to P3, two servers Server1 and Server2 and six consumers numbered C1 to C6, it is easy to transpose this model into Ingescape. For a complete demonstration, we introduce in our example three producers numbered from Producer_1 to Producer_3.
Rather than using partitions on a topic to slice up information, Ingescape allows to specialize the output of producers. Our producers therefore offer as many outputs as Kafka would use partitions, which we also number P0 to P3 but which could be named freely. These outputs can be of different type and format from each other, without depending on a single message format as Kafka imposes.
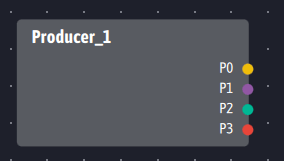
The work of dividing up the information therefore shifts from the administration of the system in Kafka to the design of the producers in Ingescape. It could seem that since Kafka allows at any time of the exploitation to modify the partitions, and gives more flexibility than Ingescape on the evolutions. However, in Kafka as in Ingescape, it is the producers who generate and structure the data. If a breakdown of the flows must be carried out a posteriori in a system, this means that the volumes or the types of data generated by the producers justify it and therefore that the latter must be modified. Most of the time, the creation of partitions in Kafka will therefore be accompanied by a modification of the producers, being reduced on the Ingescape side to an evolution of the producers and an update of the streams (the latter not requiring software development with Ingescape). We are therefore on two different representations but very similar activities in terms of effort and temporality on the producers, Ingescape taking the advantage on the flexibility of the infrastructure.
Next, Kafka imposes the presence of at least one broker to supply consumers. With Ingescape, two architectures are possible. The first is completely decentralized and puts producers and consumers in direct contact, dynamically if necessary. A producer will then have the following flows to the six consumers:
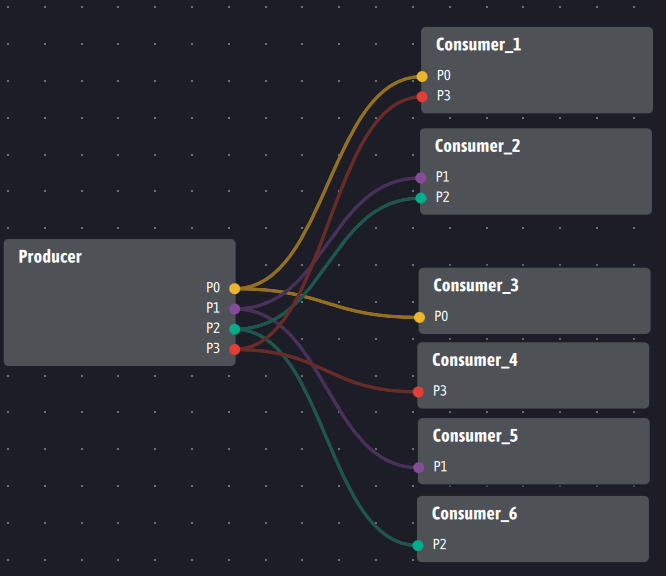
If multiple completely identical producer instances are running, the instances will be presented as clones of the Producer agent and each clone will transparently distribute its data to each of the consumers, which will receive data as it is generated from each Producer.
If several actually different Producers are involved, that is to say having in a justified way different implementations for the different Producers, definitions or functions but having a common subset of outputs P0 to P3, it is possible to use the following architecture in Ingescape:
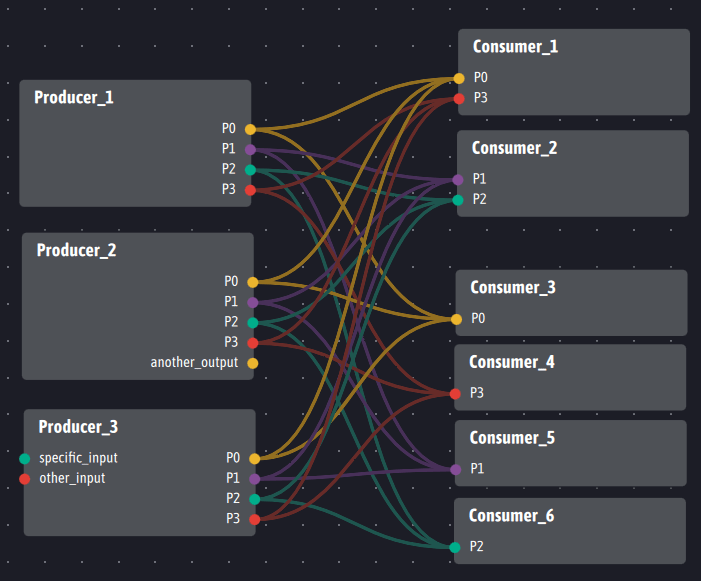
We see that the three producers are not strictly identical in terms of inputs and outputs but the three producers have exactly the same mapping of inputs/outputs with respect to the six consumers.
The reader might be concerned by the large number of links between producers and consumers, thinking that Ingescape introduces complexity on this point. In fact, the links presented above exist in the same way in Kafka and are even multiplied by two since the broker is placed in the middle of each link. First, Ingescape makes it possible to represent the reality of these links. The visual representation gives a realistic representation of the complexity when it is necessary and allows the visual detection of inconsistency. Ingescape then allows, link by link, to carry out monitoring and inspection of communications impossible by design for Kafka. Second, Ingescape’s template-based approach makes it possible to automatically generate description files for these links and transmit them – statically or dynamically – to consumers and producers without manual human labor.
Whether the producers are clones (the most common situation) or legitimately different implementations and definitions, consumers receive data in a balanced and fair way from the active producers. And in this set of situations, there is still no need, with Ingescape, to introduce a pseudo-broker carrying data between producers and consumers.
If we still want to introduce an agent serving as an intermediary between consumers and producers, Ingescape allows it as illustrated in the following diagram:
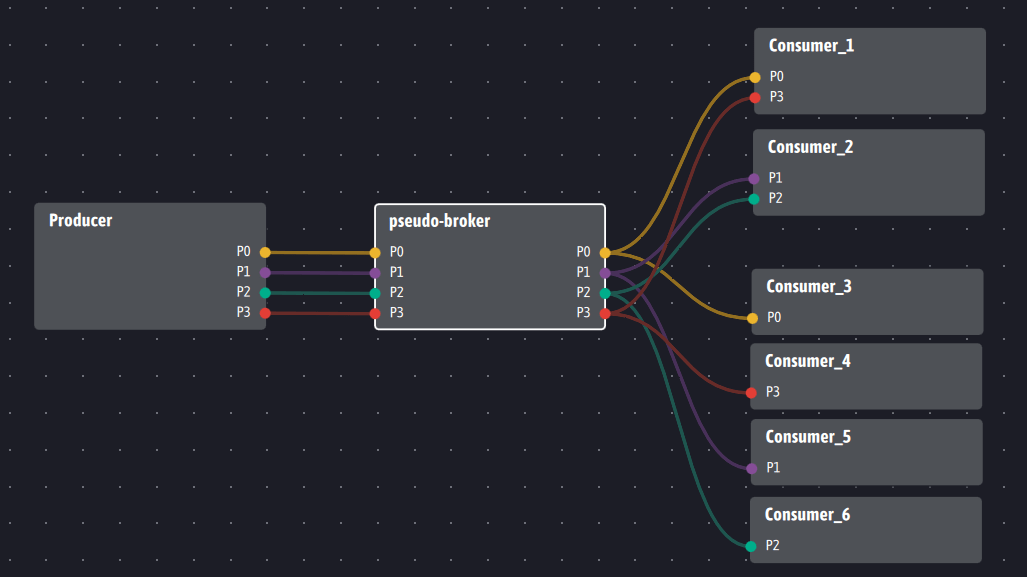
We will see in point 3 that this architecture introducing a pseudo- broker only makes sense to provide a historization service… or to smooth out any computational loads as shown in point 2 below. In any case, it remains optional with respect to producers and consumers who do not have to be modified regardless of the chosen architecture.
2- Distribution of producer streams to multiple servers
Kafka uses topic partitions to segment information between multiple servers, each hosting one or more partitions. With Ingescape, the information is segmented in the same way but through the inputs/outputs of the agents. If we are looking to reproduce with Ingescape a cluster of two Kafka servers managing four partitions numbered from P0 to P3, here is an equivalent scheme in which the producers distribute their data to two pseudo-brokers, Server1 and Server2 :
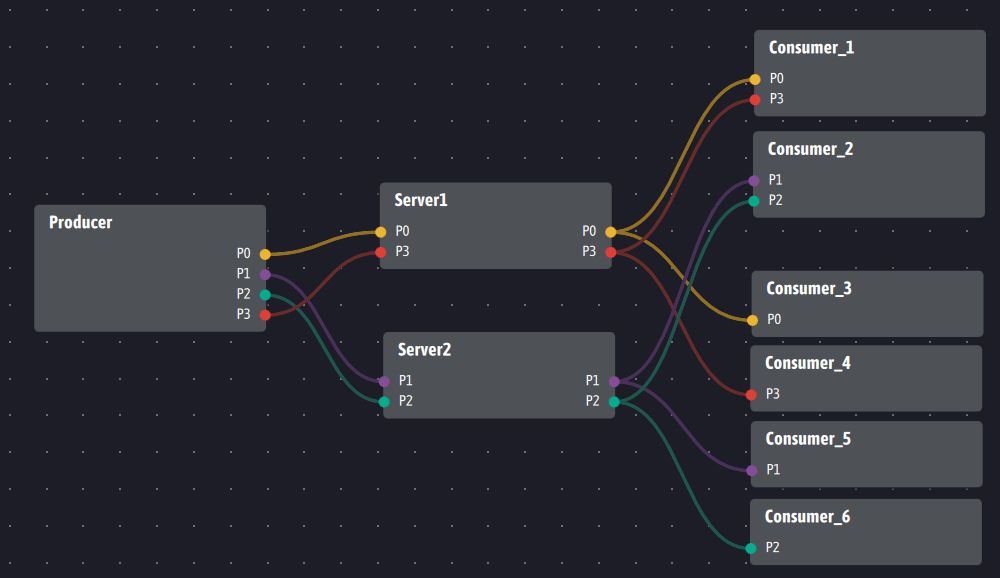
This type of architecture makes sense if and only if the agents Server1 and Server2 have proven added value with respect to the system and/or consumers, and that the flows of data coming from the producers are sufficiently important to require to distribute this load between two distinct agents. In the distributed context of Ingescape, the presence of two servers can also be justified if the servers are on separate geographical sites connected to the producer platform using Ingescape proxies . It can also be the same for consumers who can be relocated and projected on our platform using Ingescape proxies . See Ingescape Platforms – Part 1 – Distributed Architectures and the Cloud with Ingescape for more details.
At this stage, we have reproduced – with an equivalent functional level and more flexibility – in Ingescape the data flow distribution topology presented in Kafka’s illustration diagram concerning partitions and clusters. This is not out of topological necessity but to benefit, when relevant, from flexibility in the distribution of the load or the location of the software. So we can now address memory and data historization.
3- Short-term memory and historization of topics
The previous points 1 and 2 mainly illustrate notions of topology and software architecture. We now discuss the value-added services that Kafka brings to a platform, namely the short-term memory of the latest published values and the historization of these values.
In Kafka, logging is provided by topic with optional partitioning, with configurable “depth” of history. Similarly, in Ingescape, we are aiming for a short-term memory and, if necessary, a historization linked to input/output flows. This short-term memory and this historization are provided by a service which is introduced through a dedicated generic agent, which can be integrated into any existing Ingescape platform. We call this agent “Topics”. Topics is dynamic and configurable. It offers {input, output} sets corresponding to variables (or topics in the Kafka world) that we wish to memorize. The operating principle is simple. Any agent writing to a Topics entry allows the written information:
- To be immediately relayed to the corresponding output,
- To make the last published value persistent on the related output (turnkey service provided by Ingescape),
- To log the information published on Topics entries, this agent being coupled to a data lake type database and to services that can be queried by other agents.
Concretely, to transpose the example from Kafka, the Topics agent takes the following form:
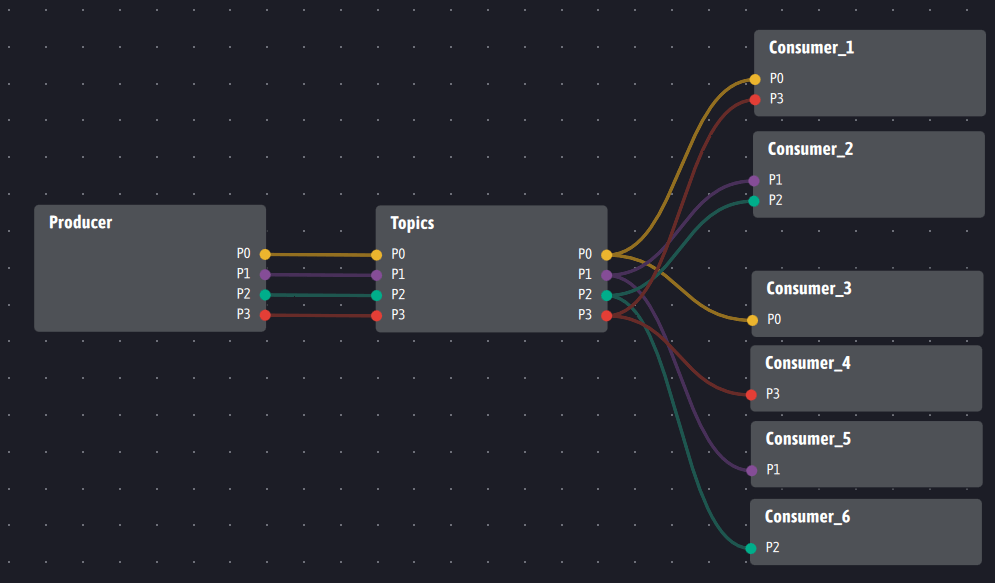
We see that Topics serves as a relay between producers and consumers like a broker Kafka does. Topics immediately renders the service of short-term memory: if a consumer arrives over time, all he has to do is link his inputs to the Topics outputs that interest it and it will immediately receive the latest published values for these outputs. Historization is ensured by feeding Topics entries, which are then stored in an associated data lake .
Topics does not necessarily have to place itself between consumers and producers to properly provide its service, in particular for historization. If for example below, consumers 5 and 6 are not interested in historization or want to avoid latency, the following architecture is to be implemented:
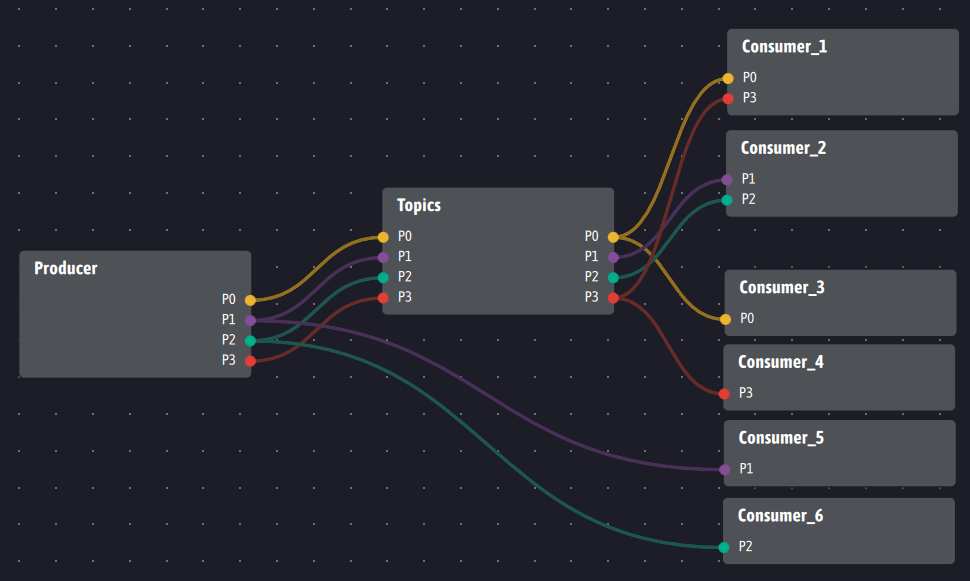
In this solution, consumers 5 and 6 are in direct contact with the producer(s) and do not benefit from the short-term memory service provided by Topics. On the other hand, the other consumers transparently benefit from the short-term memory service and consumers 5 and 6 could still benefit from historization by querying Topics, independently from the short-term memory service.
As in Kafka, the historization service cannot be provided solely by information flows. It must be carried by a service to which must be passed requests comprising additional parameters indicating for example from what date the log messages must be provided. Here are the services provided by Topics as ingescape services, where a topic is related to an {input, output} set:
- Adding and deleting a topic,
- Cleaning up a topic,
- Retrieving the values of a topic since a certain date or for a certain number of stored values.
Unlike Kafka, Ingescape does not by default impose a timestamp on its messages and does not encapsulate them in an envelope providing a unique identifier. To ensure a service completely equivalent to that of Kafka without imposing heavy envelopes on the data exchanged, Topics duplicates each output: the first output provides the raw data as explained above. The second output, necessarily of the “serialized binary data” type, publishes the same data but prefixed by a unique identifier and the native type of the data. This identifier allows consumer agents to permanently track the last data received and therefore to access a new Topic service:
- Retrieving the values of a topic from a given message, using the unique identifier of this message.
In our example, Topics then takes the following form:
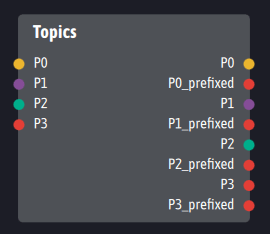
Each output is duplicated to provide a native version and an encapsulated version of the data including additional logging data.
4- Breakdown of data relayed by brokers towards consumers
This fourth point is also treated extensively by RabbitMQ. We are therefore shifting its resolution with Ingescape following the presentation of RabbitMQ which begins further down in this article.
Interoperability between Kafka and Ingescape
Similar to the approach with MQTT, Ingescape offers an agent that allows interoperability with Kafka brokers. For each topic and even each partition of topic, the Ingescape Kafka gateway exposes an {input, output} set allowing on the one hand to receive the records of a topic and on the other hand to write to connected Kafka broker or cluster.
The Ingescape Kafka gateway takes care of converting the data coming from Ingescape in the format expected by Kafka, and reciprocally structures the Kafka records so that they can be easily exploited in the Ingescape universe, with or without a historization envelope. Kafka’s {timestamp, key, value} structures are easily transposable with a {timestamp, output, value} structure in Ingescape, the timestamp being optional.
In addition, similarly to Topics, the Ingescape Kafka gateway offers services allowing users to benefit from Kafka’s historization. We therefore achieve complete interoperability between the two technologies.
Summary of the comparison between Apache Kafka and Ingescape
The key features offered by Apache Kafka are easily reproducible in Ingescape. Ingescape offers more flexibility and choices of topology and architecture to adapt to more situations. The architectures supported by Ingescape, in particular via the Cloud and the Internet, make it possible to absorb data flows of a size similar to those of Kafka, or even higher for agents operating on the same machine or on the same local network thanks to the absence by broker.
Historization and short-term memory provided as services and not as mandatory elements that must be managed or configured, give Ingescape an advantage in terms of the minimum size and complexity of the infrastructures necessary for their operation. In Ingescape, Topics is a simple agent that can be run on any platform, even after its implementation, with or without a database for historization, which remains optional.
For expert readers, we list here additional advantages of Ingescape which would deserve articles in their own right:
- In addition to brokers, Kafka also uses the Zookeeper solution for linking producers/consumers and brokers, also managing redundancy and on-the-fly flow direction services, as well as server groups (clusters) and consumer groups. Zookeeper is a complex solution often criticized for its difficulty of use and its paradoxical approach which imposes a centralized structure on a so-called “distributed coordination” system.
- Kafka programming interfaces (APIs) present a very high quantity (several thousands) of objects and functions, while Ingescape, which provides an equivalent or even better service, makes do with 75 functions in all. Kafka, even with it high-level bindings and by the need to program and manage brokers, requires weeks of practice for a correct mastery, against only a few hours for Ingescape.
- The structural implementation of Kafka in Java distances brokers from any search for performance and optimization while the brokerless approach of Ingescape and its native C implementation, using ZeroMQ’s network layers, recognized as being the fastest, offers state-of-the-art performance. It is also impressive to see how the ZeroMQ community, to which we contribute, has produced in a few days a functional clone of Kafka called Dafka which incorporates its topology principles and functionalities with already much higher levels of performance, on top of much lighter and more efficient infrastructures.
- The Kafka community is making great efforts to connect databases, manage the notions of streams, etc. All this is done with the aim of bringing the outside world back into the Kafka world, justified by the intrinsic heaviness of its infrastructures. In contrast, Ingescape maintains a very small footprint and allows with remarkable speed to integrate third- party software, legacy or new, into heterogeneous software platforms. The benefit obtained is to always be able to choose the best technologies for tasks other than communication itself: connections with databases, serialization and structuring of data, transformation and fusion of data, intelligent load balancing, gateways with self-coding generated, etc.
RabbitMQ – data stream breakdown
Like Apache Kafka, RabbitMQ is based on the concepts of producer, broker and consumer and is aimed at large-scale systems. RabbitMQ draws its originality from the following elements:
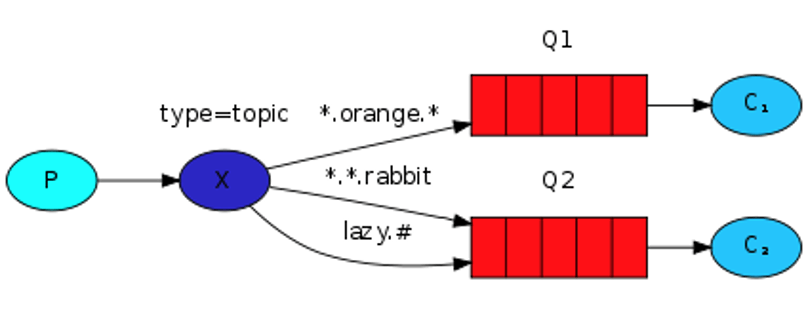
- Support for multiple protocols including MQTT, AMQP and STOMP, it therefore places itself as a service provider above communication protocols established by others,
- A RabbitMQ broker carries queues which store messages. A consumer subscribes to a given queue. If multiple consumers have subscribed to the same queue, messages from that queue will be distributed among the consumers. This makes RabbitMQ a message dispatch system for broker-driven parallel processing. This while Kafka lets consumers organize their consumption, in groups or not, by offering a history of its topics.
- Producers connect to a RabbitMQ exchange . This exchange is then responsible for distributing the messages to different queues according to fairness rules and/or an analysis of message content.
These three points are summarized in the following diagram:
Comparisons between RabbitMQ and Kafka are frequent. Often ZeroMQ is associated with these comparisons and each is highlighted for the following qualities:
- Apache Kafka: very high-speed delivery from producers to broker followed by significant latency, from broker to consumers, supported by a solid, scalable and resilient infrastructure, with better throughput than RabbitMQ,
- RabbitMQ: versatility of communication protocols, high performance in just-in-time distribution from producers to consumers with efficient referral by brokers, better latency than Kafka,
- ZeroMQ: higher performance and versatility than RabbitMQ and Kafka, inherently better and more controllable latency and throughput, no broker needed, multi-language, multi-OS, with feature-centric on communication infrastructures and architectures. The relative weakness of ZeroMQ is that it does not benefit from the same level of publicity as its two competitors carried on one side by the Apache Foundation and on the other by VMWare.
In this context, Ingescape made the founding choice to retain ZeroMQ as a “low level” communication layer, ensuring a raw performance above RabbitMQ and Kafka without the need for infrastructure, and to extend ZeroMQ with a formal but simple model for communication flows and services: agents with inputs, outputs, mappings,and services. The comparison between Kafka and Ingescape showed the advantages in terms of flexibility, without depriving Ingescape of short-term memory and a historization service when necessary. In front of RabbitMQ, Ingescape must offer a data breakdown service that we present below.
Data flow breakdown with Ingescape
By default, when an output from an Ingescape agent feeds several inputs from other agents, each of the inputs receives all the publications from the output of the producer agent. The massive data distribution scheme is more common than the one of ventilation/breakdown, i.e. data sharing between several consumers. This is why Ingescape favors it by default through mappings.
To provide data breakdown, Ingescape maintains its input and output concepts. It is therefore a question of sharing the publications of an output of a producer agent to the inputs of several consumer agents, but by splitting the outgoing data in order to distribute them among the consumers. For this, we introduce the notion of splitter ,which is an object associated with an output of an agent and allowing the latter to be relayed to inputs by distributing the publications of the output to the different inputs. A link between a splitter and an entry of an agent is called a split.
Here is the corresponding visual representation:
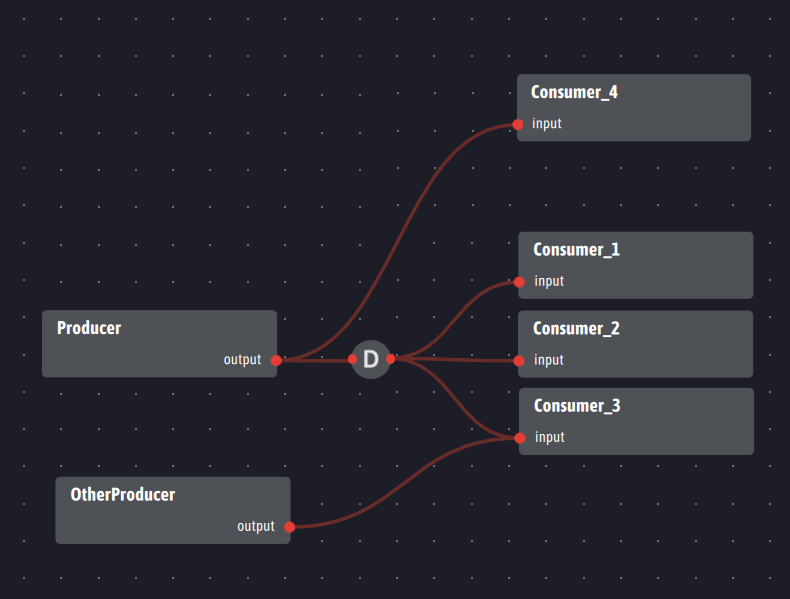
This representation shows the much greater flexibility of Ingescape in terms of topology compared to RabbitMQ’s exchanges and queues and Kafka’s consumer groups. Ingescape facilitates the structuring of the data that flows through the creation of inputs/outputs rather than the creation of topics or queues on brokers. Any output and any input can be used for both diffusion and ventilation, even simultaneously. It is Ingescape which automatically manages the distribution or the breakdown according to the created mappings and splitters.
- The “output” of the Producer feeds both a splitter to the “input” of the Consumers 1 to 3 and a classic mapping to Consumer_4: Consumer4 will receive all the data produced by Producer while Consumers 1 to 3 will only receive part of it (around 33% each) depending on their ability to ingest the data,
- The “input” of the agent OtherProducer feeds the “input” input of Consumer 3 in a classic way, in addition to the splitter attached to the Producer: this input will jointly process the data emanating from Producer and OtherProducer regardless of their origin.
When several distinct agents consume the data passing through the same splitter, they declare a quantity of “credits”, i.e. the maximum number of messages they can receive. Then, as the received data is processed, the consumers send new credits to the producer. This mechanism is called “flow regulation” and makes it possible to optimize the distribution of messages:
- An agent who has exhausted its credits on a producer will not receive new data until its has sent new credits to this producer,
- Sending more than one credit makes sending more fluid avoiding downtime between the end of processing and the return of additional credit.
Compared to the common uses of ZeroMQ, an Ingescape splitter does not allow multiple outputs to be connected. That is to say that it does not make it possible to coordinate several producers towards a set of consumers. Even if it would be technically possible for Ingescape to use the flow control mechanism between several producers and consumers simultaneously, the cost/benefit ratio is not favorable to the simplest solution, especially since the scheme with a single producer and multiple consumers is by far the most common. This solution simply consists of introducing an agent, which can be a Topics instance or a specifically developed agent, which groups together several producers on its input(s) and relays the information via its output(s) to one or more >splitters. In this architecture, producers are handled by fair queuing and consumers are handled using flow control, which brings us back to the same efficient topology as RabbitMQ… with more flexibility.
Interoperability between RabbitMQ and Ingescape
To publish information from an Ingescape platform to a RabbitMQ exchange , the principle remains the same as for Apache Kafka and MQTT: an Ingescape RabbitMQ gateway exposes one or more inputs per exchange and takes care of converting the data arriving to these inputs into a RabbitMQ message destined for the exchange.
Spreading RabbitMQ data streams to consumers queues means that any Ingescape RabbitMQ gateway posing as a consumer will receive only part of the data emitted by the queue, in accordance with the principle of ventilation/breakdown. It seems irrelevant to use Ingescape to receive only a limited part of the information from the corresponding RabbitMQ platform. It is likely that consumer-side interoperability will only really make sense if one wants to fully delegate the processing of one or more queues to an Ingescape platform. We must therefore consider precisely the architecture of the RabbitMQ platform whose data we wish to consume in order to process the data in an appropriate manner. However, from a strictly technical point of view, an Ingescape RabbitMQ gateway capable of consuming data from RabbitMQ is very easy to develop.
To give more flexibility with respect to the context of RabbitMQ, we have separated the Ingescape RabbitMQ gateway into two different agents: one is dedicated to sending information from Ingescape to an exchange, the other exploits one or more RabbitMQ queues to expose them as gateway agent outputs to the Ingescape platform concerned.
General summary – Ingescape versus MQTT, RabbitMQ and Apache Kafka
This article discusses how Ingescape can support similar topologies and architectures as MQTT, Apache Kafka, and RabbitMQ do. For the vast majority of needs, the intrinsic properties of Ingescape respond directly to the identified needs and allow system designers to choose the Ingescape platform topology that best suits them, including locally, between remote platforms and with remote clients.
Historization, a feature of Apache Kafka, is included in Ingescape as a service, in the form of a dedicated Topics agent using an Apache Cassandra database… or any other suitable technology. Ingescape wishes to solve in the future the problem of synchronization between the output streams of the agents and the historization requests in order to offer greater transparency to Kafka, which also requires specific code to be written by the developers. In the current state of its implementation, with the use of the Topics agent, Ingescape is already at the same level as Kafka.
Data dispatching required to introduce into the Ingescape formalism the concept of splitter which is completely supported by the Ingescape library and can be visually exploited through the Ingescape editor. The challenge we faced was to preserve the simplicity of the concepts and the ability to be visually managed via the Ingescape tools suite, without requiring software code in the agents using the splitters via the library.
The major points brought by Ingescape compared to MQTT, RabbitMQ and Apache Kafka are:
- Does not require brokers to implement heterogeneous yet high performance distributed systems,
- Structure and distribute information through inputs/outputs rather than through topics, gaining flexibility and dynamicity during execution, and proposing robust and resilient architectures,
- Through gateways, offer complete and simple interoperability with these three major solutions as well as other solutions belonging to the large family of software buses,
- Maintain a formal and verifiable description of topologies and interface contracts, guaranteeing lasting bridges with the worlds of system architecture, automatic code generation and verification/validation,
- Guarantee a much greater openness than Apache Kafka and RabbitMQ on the integration of and in third-party technologies, including communication technologies and network security.
Read next
Following this article, two additional articles are available: