
Ingescape propose un modèle de communication distribuée entre logiciels permettant d’une part des appels de services et d’autre part une circulation de flux d’informations entre logiciels, quels que soient leur langage de programmation et le système d’exploitation sur lequel ils fonctionnent. Ce sont les flux d’information ou dataflows qui constituent la plus grande force d’Ingescape en rendant enfin accessible la mise en œuvre de plateformes hétérogènes fortement interopérables mais complètement décentralisées, dépassant largement l’État de l’Art des solution industrielles actuelles.
L’approche à base de flux d’information permet un couplage très faible et une réutilisabilité très forte entre les composants logiciels d’un système. La gestion dynamique des flux dans Ingescape offre une adaptation en temps réel mais aussi au fil des évolutions même conséquentes d’un environnement donné.
Pour exposer les bénéfices de l’utilisation des flux d’information et les qualités d’Ingescape dans ce contexte, nous présentons dans cet article trois technologies majeures autour des bus logiciels et des flux d’information : MQTT, Apache Kafka et RabbitMQ. L’analyse de ces trois technologies et leur comparaison avec Ingescape donnera au lecteur tous les éléments pour appréhender les qualités de ce type de solutions en général et les atouts d’Ingescape par rapport à des technologies souvent plus complexes et paradoxalement moins efficaces ou moins polyvalentes.
Si ce n’est déjà fait, nous recommandons préalablement la lecture de Plateformes Ingescape – Partie 1 – Les architectures distribuées et le cloud avec Ingescape.
MQTT – topics et brokers
MQTT est une solution de communication massivement utilisée dans le monde de l’internet des objets. Imposant un surcoût très faible par rapport aux données brutes à transporter, elle est très prisée dans un domaine où chaque octet est compté pour préserver l’autonomie des équipements en énergie et les modèles économiques sur le transit des données.
MQTT est l’archétype des bus de communication centralisés : un broker sert de relai de communication entre des producteurs d’informations et des consommateurs de ces mêmes informations. De multiples producteurs et consommateurs peuvent se mettre en relation avec le broker, permettant une relation entre eux plus souple que des approches client/serveur traditionnelles. La communication entre producteurs et consommateurs se fait autour de la notion de topic. Un topic peut être vu comme un canal de communication partagé et ouvert. Les consommateurs s’abonnent aux topics qui les intéressent et les producteurs publient de l’information sur un topic donné. Tout consommateur abonné à ce topic reçoit alors l’information publiée. C’est un principe simple qui s’apparente à celui des messageries et outils de discussion entre personnes, comme il en existe depuis longtemps.
Dans l’illustration ci-dessous, un véhicule – producteur – utilise MQTT pour transmettre sa vitesse. L’information de vitesse est relayée via un topic baptisé « speed ». Un téléphone mobile et un serveur de données – des consommateurs – s’abonnent à ce topic et reçoivent les informations via le broker au fur et à mesure des publications du producteur.
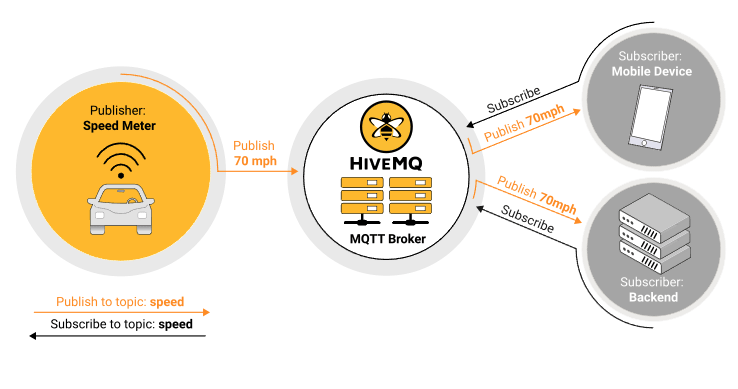
Dans ce type de solutions, le broker est un serveur central servant à la fois à la gestion des connexions des producteurs et consommateurs et au transit de l’information entre ces derniers. C’est un nœud sur un système dont la défaillance bloque l’ensemble des consommateurs et producteurs qui l’utilisent et qui peut constituer un goulot d’étranglement en termes de bande passante. Le passage obligé des informations par le broker induit aussi une latence supplémentaire inévitable.
Ingescape est une solution brokerless
Le paragraphe précédent met en avant les inconvénients classiquement reconnus pour les bus logiciels à base de brokers. Ingescape fait le choix différent de proposer un système complètement décentralisé dans lequel les producteurs et les consommateurs – que nous appelons indistinctement des agents – constituent un réseau maillé. Dans une plateforme Ingescape, les agents se connaissent mutuellement grâce au maillage réalisé automatiquement.
Dans la majorité des cas, le maillage est réalisé à l’aide d’un système d’auto-découverte entre agents. Dans les rares cas où ce mécanisme ne peut pas être utilisé, il existe des brokers Ingescape dont l’usage se limite à la mise en relation entre agents, ce qui correspond à la définition concrète d’un broker qui ne devrait pas porter le poids des transactions entre les autres acteurs. Avec Ingescape, les données transitent ensuite directement de pair à pair, ce qui différencie les brokers Ingescape des brokers au sens MQTT, Kafka ou RabbitMQ, plus proches de serveurs classiques.
C’est un point fondamental pour Ingescape : la mise en place d’une plateforme Ingescape composée de multiples agents ne nécessite que les agents eux-mêmes sans infrastructure ni administration additionnelle, que ce soit sur un même ordinateur ou sur un même réseau. Cette souplesse et cette facilité de mise en œuvre rendent Ingescape complètement adapté à une utilisation en contextes de prototypage sur des environnements temporaires, tout comme pour des plateformes industrielles riches et robustes.
Chaque agent étant à la fois un producteur et un consommateur, nous modélisons les agents sous forme de « boites » indépendantes les unes des autres, exposant des « entrées » et des « sorties ». Les entrées d’un agent peuvent être reliées – nous parlons de mapping – aux sorties d’autres agents. Une sortie d’un agent peut être reliée à un nombre indéterminé d’entrées d’autres agents et une entrée d’un agent peut être alimentée par un nombre indéterminé de sorties d’autres agents.
Avec Ingescape, l’exemple donné pour illustrer MQTT se présente de la façon suivante :
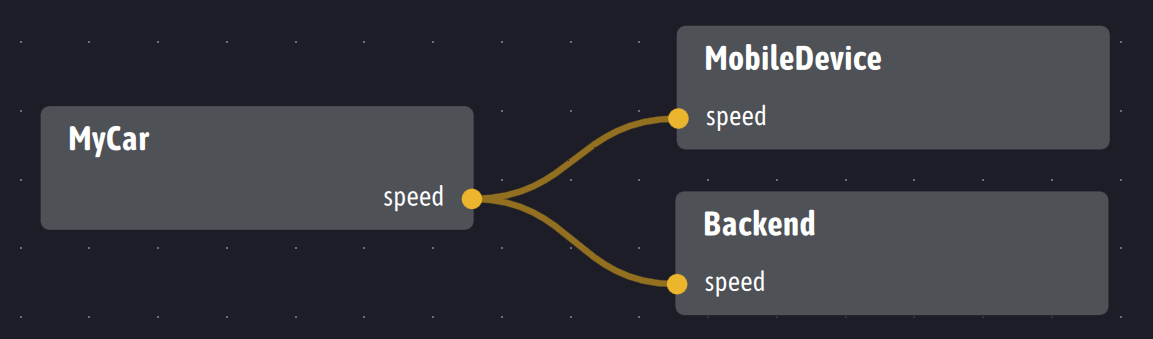
Dans un système complètement décentralisé, les relations entre entrées et sorties se substituent avantageusement aux topics en utilisant des communications pair à pair. Les systèmes utilisant Ingescape se matérialisent sous la forme d’agents logiciels qui, selon leur rôle, sont capables de recevoir et d’émettre de l’information, nommée et typée, avec un système résultant qui est une composition d’agents et de flux d’information entre ces derniers. Sous cet angle, une plateforme Ingescape est un ensemble d’agents exposant des entrées et sorties reliées entre elles par un mapping.
Un bénéfice indirect – et néanmoins majeur – de l’utilisation d’Ingescape est la capacité à visualiser et à superviser la totalité d’un système et pas seulement les points centraux appelés brokers dans les autres technologies : la présence des agents, les flux d’information échangés (ainsi que les requêtes/réponses via les services qui ne sont pas le sujet de cet article) sont observables en temps-réel au travers de la suite logicielle Ingescape Circle. De plus, chaque agent étant caractérisé à la fois comme consommateur et producteur, ce sont les agents qui portent la topologie d’un système, sans avoir à introduire les intermédiaires que sont les brokers, pouvant nuire à la fois à la représentation des flux d’information et à sa circulation fluide.
Les capacités d’Ingescape, pour les réseaux locaux reliés à des plateformes ou clients distants, exposées dans l’article Plateformes Ingescape – Partie 1 – Les architectures distribuées et le cloud avec Ingescape, exposent les limites des solutions à base de brokers et topics telles que MQTT et les limitent de fait à des environnements très contraints où même un signal de vie doit être évité pour économiser de la bande passante. Dès qu’une connexion TCP ou UDP est possible, Ingescape apporte immédiatement plus de souplesse et une meilleure capacité de supervision et de contrôle.
Interopérabilité entre MQTT et Ingescape
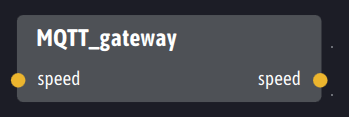
Ingescape propose un agent passerelle générique dédié à l’interopérabilité avec MQTT. Cette passerelle se connecte à un broker MQTT et en expose dynamiquement les topics sous la forme de doublets {entrée, sortie}. Si le broker MQTT reçoit une publication sur un topic, la passerelle Ingescape MQTT relaie à son tour cette publication sur sa sortie correspondante. Symétriquement, si un agent Ingescape veut publier sur un topic MQTT, il écrit sur l’entrée correspondante de la passerelle qui se charge ensuite de la relayer au topic MQTT correspondant.
Pour notre exemple « speed », voici la forme que prend la passerelle Ingescape MQTT :
Les topics ou channels dans Ingescape
D’abord introduite pour des besoins de communication dans son réseau maillé d’agents, Ingescape propose une capacité de communication par topics – ou channels qui sont l’autre nom usuel de ce paradigme. Dans ce paradigme, n’importe quel agent peut publier sur des channels et n’importe quel autre agent peut s’abonner aux channels de son choix et ainsi recevoir les messages qui y sont publiés. Ce mécanisme est utilisé pour maintenir la cohérence interne entre agents. Il reste accessible aux utilisateurs qui le souhaitent et qui peuvent utiliser leurs propres channels. Contrairement à MQTT et aux autres solutions de la même famille, cette communication par channels proposée par Ingescape ne réclame toujours pas de broker et reste complètement décentralisée.
Apache Kafka – flux massifs, historisation des échanges, scalabilité des brokers et consommateurs
Toujours autour des concepts de producteur, consommateur, topics et brokers, Apache Kafka est la solution de référence pour les échanges massifs de données sur des échelles géographiques et matérielles de niveau mondial.
Apache Kafka se distingue par deux éléments majeurs :
- Les brokers Kafka ont une capacité de mémoire immédiate et d’historisation qui permet aux consommateurs d’accéder aux valeurs passées d’un topic donné,
- Kafka propose une gestion topologique avancée des brokers et des consommateurs, permettant une redondance et un partitionnement des brokers en clusters, ainsi qu’une ventilation de données vers les consommateurs qui sait également tirer avantage des partitions.
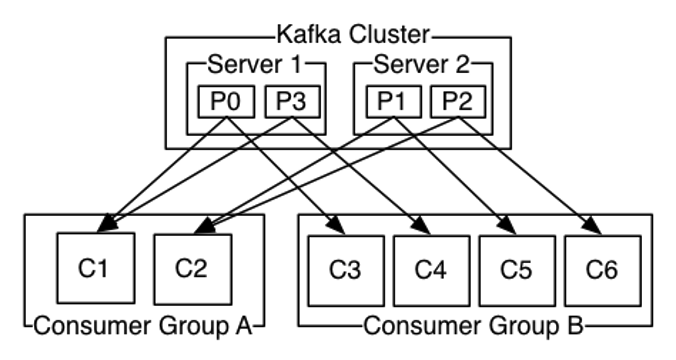
Voici le modèle général des communications dans Apache Kafka :
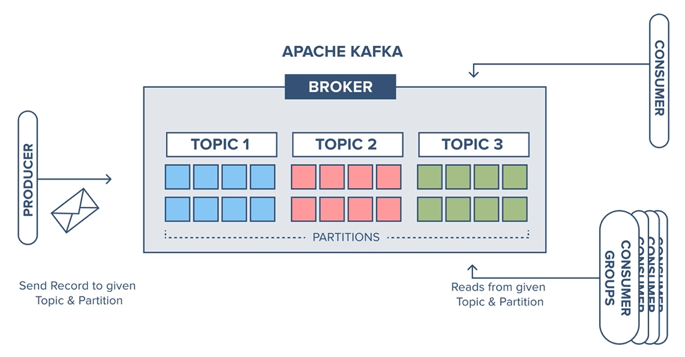
Nous y retrouvons des producteurs, consommateurs, brokers et topics. Avec Kafka, les topics peuvent être segmentés en partitions, c’est à dire en groupes disjoints. Ces partitions peuvent être établies selon une ou des « clés » spécifiques telles que le producteur d’origine ou les données – structurées sous la forme de clés/valeurs – contenues dans les messages. Les partitions peuvent exploiter la présence d’une clé ou la valeur associée à une clé donnée pour insérer une nouvelle entrée – appelée un record – dans une partition spécifique d’un topic.
Les topics sont des piles de données. Une entrée dans un topic est appelée un record. Les records sont stockés et ordonnés dans chaque topic ou chaque partition de topic. Les consommateurs ont donc la possibilité d’accéder à l’historique des records d’un topic ou d’une partition pour pouvoir reprendre leurs traitements à partir d’une certaine date ou bien de la dernière valeur qu’ils avaient obtenus. Par défaut, il est aussi possible de récupérer seulement le dernier record inséré mais aussi la totalité des records stockés, ce qui peut représenter un volume de données très important. Ce mécanisme d’historisation impose aux messages Kafka, c’est à dire aux records, de comporter des informations additionnelles quant à leur indexation afin que les consommateurs puissent identifier leur rang ou bien leur date et procéder à des requêtes auprès des brokers pour récupérer les records plus récents ou plus anciens que leur index de référence. De même, la réception d’un message réclame un traitement concernant son index et induit des messages plus lourds sur le réseau que MQTT par exemple.
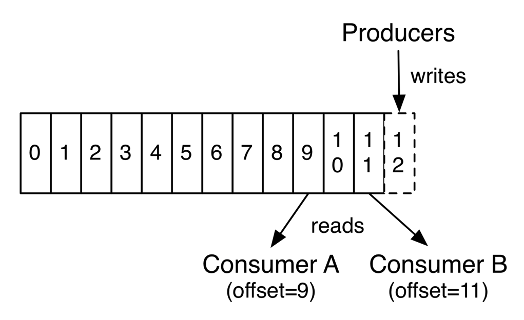
Pour distribuer la charge de stockage et de traitement, les brokers peuvent être découpés en clusters, c’est à dire en ensemble de serveurs pouvant se partager les différentes partitions d’un topic donné. La synchronisation entre serveurs pour que chacun sauvegarde in fine l’ensemble des données d’un topic est réalisée de façon asynchrone et en tâche de fond par les infrastructures Kafka. De plus, les consommateurs peuvent être associés dans des groupes et se partager, au sein d’un groupe, les différentes partitions. Selon le nombre de consommateurs dans un groupe et le nombre de partitions, Kafka gère la distribution de la charge et des données vers les consommateurs de chaque groupe, avec des possibilités de redondance à chaud impliquant des consommateurs « de secours ».
Apache Kafka propose des solutions avancées et originales quant à la pérennité des informations, à la gestion distribuée de très gros volumes de données entre serveurs et vers les consommateurs. La gestion de charge vers les consommateurs est également au cœur de la technologie RabbitMQ. Nous y revenons donc plus loin dans cet article pour comparer Kafka et RabbitMQ à Ingescape sur ce sujet précis. Nous allons d’abord comparer ici Apache Kafka et Ingescape sur le plan de la pérennité des données et de la gestion de charge sur les brokers/serveurs.
Historisation de l’information et scalabilité des flux de données avec Ingescape
La contrepartie de la forte capacité de distribution et d’historisation d’Apache Kafka sont la complexité élevée et la lourdeur de sa mise en œuvre et l’administration des plateformes associées. A ce titre, Kafka est plutôt utilisé par des entreprises de taille importante ayant la capacité de mobiliser une ou plusieurs équipes de maintenance et des infrastructures matérielles significatives hébergeant les brokers. Enfin, le modèle producteur / broker / consommateur rend Kafka peu performant pour les systèmes ayant besoin de manipuler de très grandes quantités d’information mais avec une très faible latence et un très haut débit local. Kafka prend son sens plutôt pour des systèmes impliquant des réseaux éloignés géographiquement.
Pour qu’Ingescape puisse proposer des services équivalents à ceux de Kafka sur l’historisation et la scalabilité des brokers, voici les points à aborder :
- Reproduction dans Ingescape de l’architecture Kafka du schéma ci-dessus
- Distribution des flux des producteurs entre plusieurs serveurs d’un cluster,
- Mémoire immédiate et historisation des topics, c’est à dire des données communiquées par les producteurs,
- Ventilation des données relayées par les brokers vers des consommateurs.
1- Reproduction de l’architecture Kafka du schéma ci-dessus avec les concepts Ingescape
Intéressons-nous en premier lieu à la nécessité ou pas de l’introduction d’un broker dans Ingescape. Si nous reprenons l’exemple Kafka ci-dessus avec quatre partitions numérotées P0 à P3, deux serveurs Server1 et Server2 et six consommateurs numérotés C1 à C6, il est simple de transposer ce modèle dans Ingescape. Pour une démonstration complète, nous introduisons dans notre exemple trois producteurs numérotés de Producer_1 à Producer_3.
Plutôt que d’utiliser des partitions sur un topic pour découper l’information, Ingescape permet de spécialiser les sorties des producteurs. Nos producteurs proposent donc autant de sorties que Kafka utiliserait de partitions, que nous numérotons également P0 à P3 mais qui pourraient être nommées librement. Ces sorties peuvent être de type et de format différents les unes des autres, sans dépendre d’un format de message unique comme Kafka l’impose.
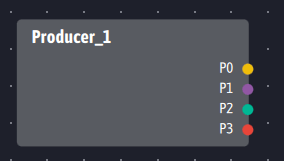
Le travail de découpage de l’information se déporte donc de l’administration du système dans Kafka vers la conception des producteurs dans Ingescape. Il pourrait sembler que puisque Kafka permet à tout moment de l’exploitation de modifier les partitions, il donne davantage de souplesse qu’Ingescape sur les évolutions. Pourtant, dans Kafka comme dans Ingescape, ce sont bien les producteurs qui génèrent et structurent la donnée. Si un découpage des flux doit être réalisé a posteriori dans un système, cela signifie que les volumes ou les types de données générés par les producteurs le justifient et donc que ces derniers doivent être modifiés. La plupart du temps, la création de partitions dans Kafka sera donc accompagnée d’une modification des producteurs, se ramenant côté Ingescape à une évolution des producteurs et une mise à jour des flux (cette dernière ne réclamant pas de développement logiciel avec Ingescape). Nous sommes donc sur deux représentations différentes mais des activités très similaires en termes d’efforts et de temporalité sur les producteurs, Ingescape prenant l’avantage sur la souplesse de l’infrastructure.
Ensuite, Kafka impose la présence d’au moins un broker pour alimenter les consommateurs. Avec Ingescape, deux architectures sont possibles. La première est complètement décentralisée et met en relation directe, dynamiquement si besoin, les producteurs et consommateurs. Un producteur aura alors les flux suivants vers les six consommateurs :
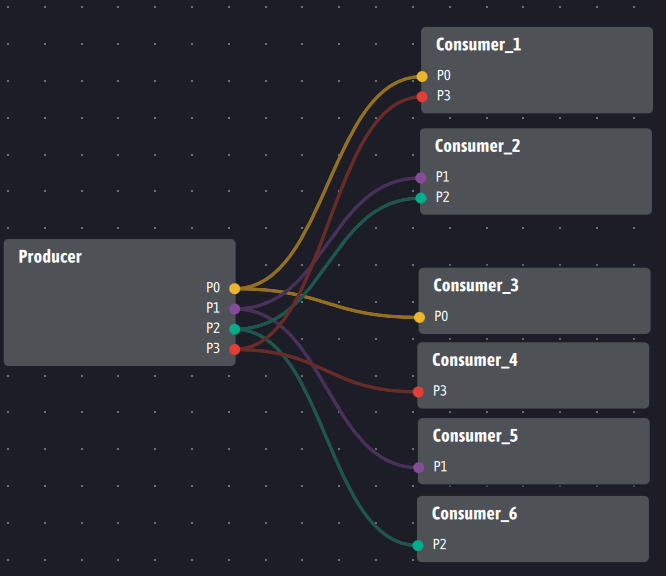
Si plusieurs instances de producteurs complètement identiques sont exécutées, les instances seront présentées comme des clones de l’agent Producer et chaque clone distribuera de façon transparente et coordonnée ses données vers chacun des consommateurs, lesquels recevront les données au fil de leur génération depuis chaque producteur.
Si jamais plusieurs producteurs réellement différents, c’est-à-dire ayant de façon justifiée des implémentations, des définitions ou des fonctions différentes mais possédant un sous-ensemble commun de sorties P0 à P3, il est possible d’utiliser l’architecture suivante dans Ingescape :
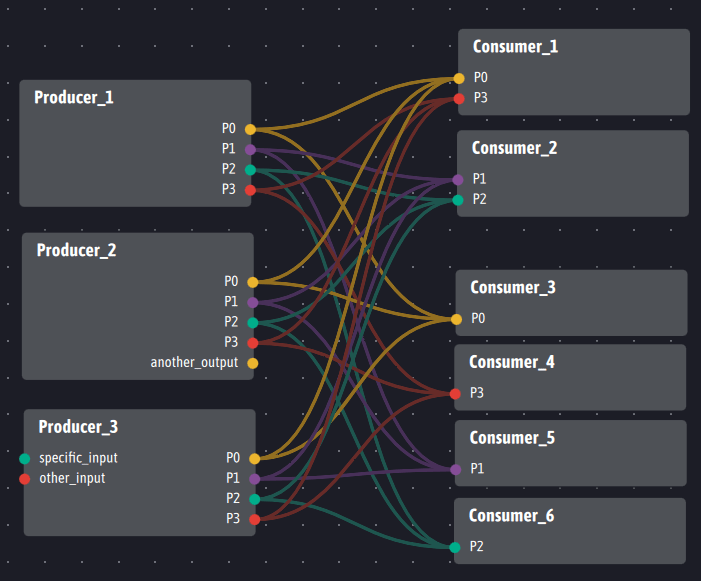
Nous voyons que les trois producteurs ne sont pas strictement identiques en termes d’entrées et de sorties mais les trois producteurs possèdent exactement le même mapping d’entrées/sorties vis à vis des six consommateurs.
Le lecteur pourrait être inquiété par le grand nombre de liens ci-dessus entre les producteurs et les consommateurs, pensant qu’Ingescape induit de la complexité sur ce point. Dans les faits, les liens présentés ci-dessus existent de la même manière dans Kafka et sont même multipliés par deux puisque le broker est placé en médiateur de chaque lien. Ingescape permet d’abord de représenter la réalité de ces liens. La représentation visuelle donne une représentation fidèle de la complexité quand cela est nécessaire et permet la détection visuelle d’incohérence. Ingescape permet ensuite, lien par lien de réaliser une surveillance et une inspection des communications impossibles par construction pour Kafka. Enfin, l’approche à base de modèles d’Ingescape permet de générer automatiquement les fichiers de description de ces liens et de les transmettre – de façon statique ou dynamique – aux consommateurs et producteurs sans travail humain manuel.
Que les producteurs soient des clones (situation la plus fréquente) ou des implémentations et des définitions légitimement différentes, les consommateurs reçoivent les données de façon équilibrée et équitable depuis les producteurs présents. Et dans cet ensemble de situations, il n’y a toujours pas de nécessité d’introduire un pseudo-broker faisant le relai entre producteurs et consommateurs.
Si nous souhaitons tout de même introduire un agent servant d’intermédiaire entre consommateurs et producteurs, Ingescape le permet comme l’illustre le schéma suivant :
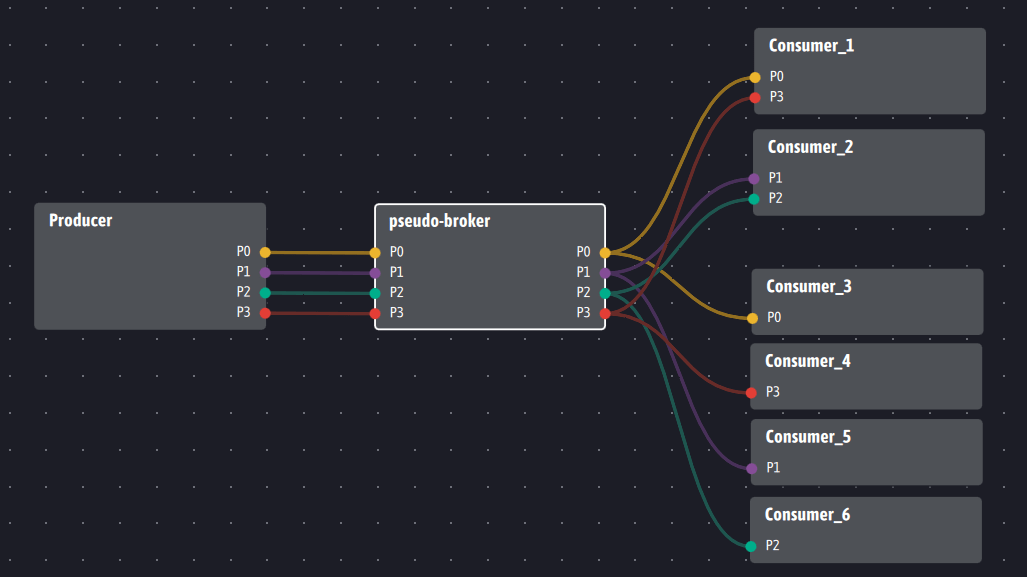
Nous verrons dans le point 3 que cette architecture introduisant un pseudo-broker n’a de sens que pour assurer un service d’historisation… ou bien pour lisser des éventuelles charges de calcul comme montré dans le point 2 ci-dessous. Dans tous les cas, elle reste facultative vis à vis des producteurs et consommateurs qui n’ont pas à être modifiés quel que soit le choix réalisé.
2- Distribution des flux des producteurs vers plusieurs serveurs
Kafka utilise les partitions d’un topic pour segmenter les informations entre plusieurs serveurs, chacun hébergeant une ou plusieurs partitions. Avec Ingescape, l’information est segmentée de la même manière mais au travers des entrées/sorties des agents. Si nous cherchons à reproduire avec Ingescape un cluster de deux serveurs Kafka gérant quatre partitions numérotées de P0 à P3, voici un schéma équivalent dans lequel les producteurs distribuent leurs données vers deux pseudo-brokers, Server1 et Server2 :
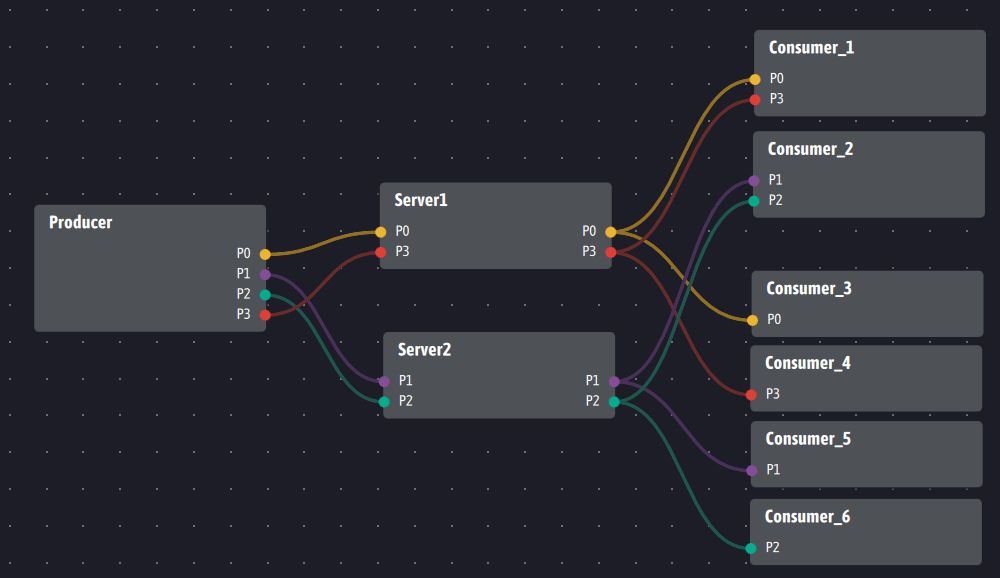
Ce type d’architecture a du sens si et seulement si les agents Server1 et Server2 ont une valeur ajoutée avérée vis à vis du système et/ou des consommateurs, et que les flux de données venant des producteurs sont suffisamment importants pour nécessiter de distribuer cette charge entre deux agents distincts. Dans le contexte distribué d’Ingescape, la présence de deux serveurs peut également être justifiée si les serveurs sont sur des sites géographiques distincts reliés à la plateforme des producteurs à l’aide de proxies Ingescape. Il peut d’ailleurs en être de même pour les consommateurs qui peuvent être délocalisés et projetés sur notre plateforme à l’aide des proxies Ingescape. Voir Plateformes Ingescape – Partie 1 – Les architectures distribuées et le cloud avec Ingescape pour plus de détails.
A ce stade, nous avons reproduit – avec un niveau fonctionnel équivalent et davantage de souplesse – dans Ingescape la topologie de distribution des flux de données présentée dans le schéma d’illustrations de Kafka concernant les partitions et les clusters. Ceci non par nécessité topologique mais pour bénéficier, lorsque cela est pertinent, de souplesses dans la distribution de la charge ou la localisation des logiciels. Nous pouvons donc maintenant aborder la mémoire et l’historisation des données.
3- Mémoire immédiate et historisation des topics
Les points 1 et 2 précédents concernent principalement des notions de topologie et d’architecture logicielle. Nous abordons maintenant les services à valeur ajoutée que Kafka apporte à une plateforme, à savoir la mémoire immédiate des dernières valeurs publiées et l’historisation de ces valeurs.
Dans Kafka, l’historisation est assurée par topic avec un découpage facultatif en partitions, avec une « profondeur » configurable de l’historique. De même, dans Ingescape, nous visons une mémoire immédiate et, si nécessaire, une historisation reliée à des flux entrées/sorties. Cette mémoire immédiate et cette historisation sont assurées par un service qui est introduit par le biais d’un agent dédié, intégrable à toute plateforme Ingescape existante. Nous appelons cet agent « Topics ». Topics est dynamique et paramétrable. Il propose des doublets {entrée, sortie} correspondant à des variables (ou topics dans le monde Kafka) que nous souhaitons mémoriser. Le principe de fonctionnement est simple. Tout agent écrivant sur une entrée de Topics permet à l’information écrite :
- D’être immédiatement relayée vers la sortie correspondante,
- De rendre la dernière valeur publiée persistante sur la sortie concernée (service clé en main fourni par Ingescape),
- D’historiser les informations publiées sur les entrées de Topics, cet agent étant couplé à une base de données de type data lake et à des services interrogeables par les autres agents.
Concrètement, pour transposer l’exemple issu de Kafka, l’agent Topics prend la forme suivante :
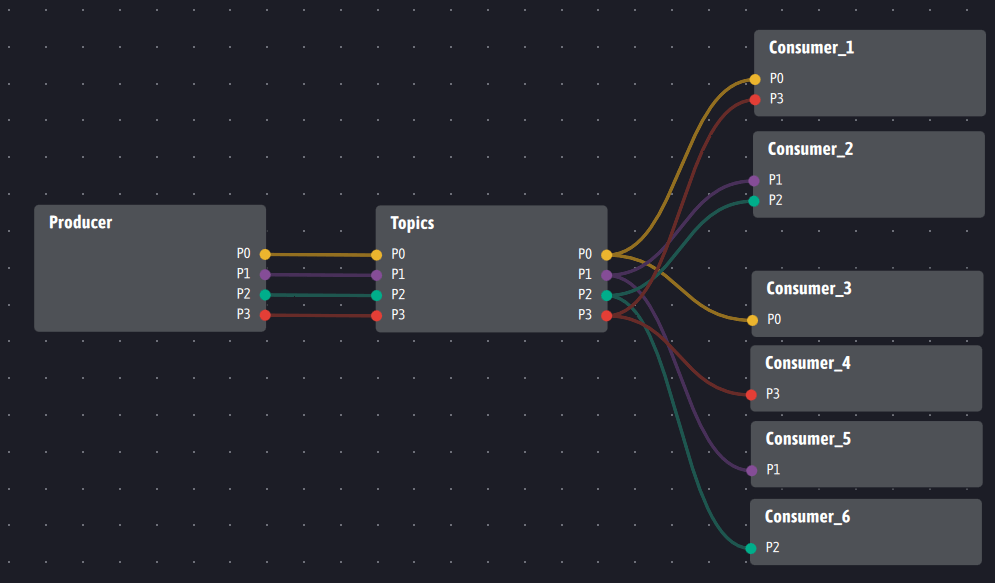
Nous voyons que Topics sert de relai entre les producteurs et les consommateurs comme le fait un broker Kafka. Topics rend immédiatement le service de mémoire : si un consommateur arrive au fil du temps, il lui suffit de lier ses entrées aux sorties de Topics qui l’intéressent et il recevra dans la foulée les dernières valeurs publiées pour ces sorties. L’historisation est assurée par alimentation des entrées de Topics, lesquelles sont alors stockées dans un data lake associé.
Topics ne doit pas nécessairement se placer entre les consommateurs et les producteurs pour rendre correctement son service, notamment d’historisation. Si par exemple ci-dessous, les consommateurs 5 et 6 ne sont pas intéressés par ou veulent éviter pour des raisons de latence le service de mémoire immédiate rendu par Topics, l’architecture suivante est à mettre en place :
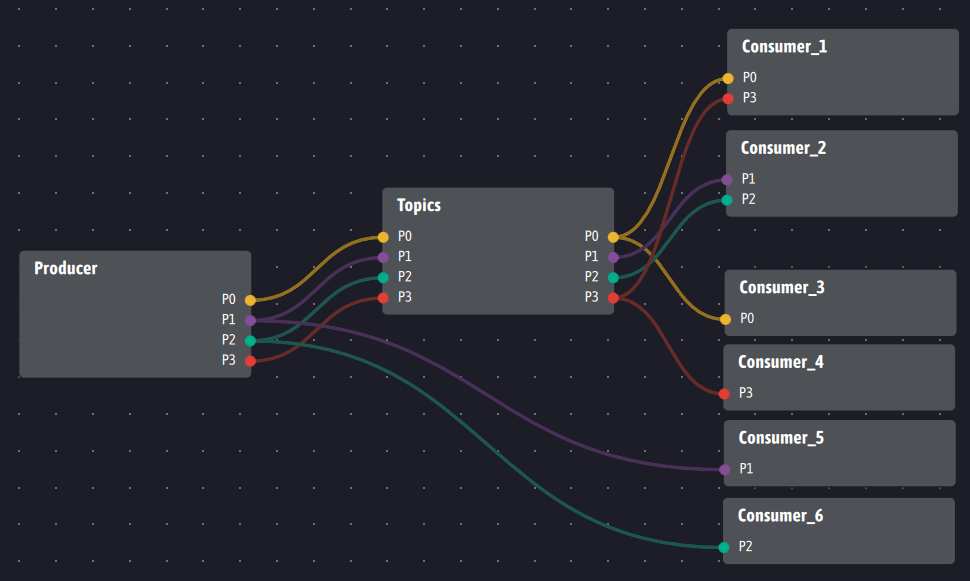
Dans cette solution, les consommateurs 5 et 6 sont en liaison directe avec le ou les producteurs et ne bénéficient pas du service de mémoire immédiate assurée par Topics. Par contre, les autres consommateurs bénéficient de façon transparente du service de mémoire immédiate et les consommateurs 5 et 6 pourraient tout de même bénéficier de l’historisation en interrogeant Topics, indépendamment du service de mémoire immédiate.
Comme dans Kafka, le service d’historisation ne peut être assuré uniquement par des flux d’information. Il doit être porté par un service auquel doivent être passés des requêtes comportant des paramètres complémentaires indiquant par exemple depuis quelle date les messages d’historique doivent être fournis. Voici les services fournis par Topics sous forme d’ingescape services, dans lesquels un topic désigne un doublet {entrée, sortie} :
- Ajout et suppression d’un topic,
- Nettoyage de l’historique d’un topic,
- Récupération des valeurs d’un topic depuis une certaine date ou un certain nombre de valeurs stockées.
Contrairement à Kafka, Ingescape n’impose pas par défaut de timestamp à ses messages et n’encapsule pas ces derniers dans une enveloppe fournissant un identifiant unique. Pour assurer un service complètement équivalent à celui de Kafka sans pour autant imposer des enveloppes lourdes aux données échangées, Topics duplique chaque sortie : la première sortie fournit la donnée brute comme exposé ci-dessus. La seconde sortie, forcément de type « donnée binaire sérialisée », publie la même donnée mais préfixée par un identifiant unique et le type natif de la donnée. Cet identifiant permet aux agents consommateurs de tracer en permanence quelle est la dernière donnée reçue et donc d’accéder à un nouveau service de Topic :
- Récupération des valeurs d’un topic depuis un message donné, via l’identifiant unique de ce message.
Dans notre exemple, Topics prend alors la forme suivante :
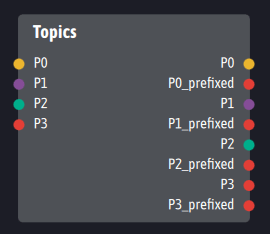
Chaque sortie est doublée pour proposer une version native et une version encapsulée de la donnée comportant les données complémentaires d’historisation.
4- Ventilation des données relayées par les brokers vers des consommateurs
Ce quatrième point est également traité de façon avancée par RabbitMQ. Nous décalons donc sa résolution avec Ingescape à la suite de la présentation de RabbitMQ qui commence plus bas dans cet article.
Interopérabilité entre Kafka et Ingescape
De façon similaire à l’approche avec MQTT, Ingescape propose un agent qui permet l’interopérabilité avec les brokers Kafka. Pour chaque topic et même chaque partition de topic, la passerelle Ingescape Kafka expose un doublet {entrée, sortie} permettant d’une part de recevoir les records d’un topic et d’autre part d’écrire vers le broker ou le cluster Kafka connecté.
La passerelle Ingescape Kafka se charge de convertir les données venant d’Ingescape dans le format attendu par Kafka, et réciproquement structure les records Kafka pour qu’ils soient exploitables facilement dans l’univers Ingescape, que ce soit avec ou sans enveloppe d’historisation. Les structures {timestamp, clé, valeur} de Kafka sont facilement transposables avec une structure {timestamp, sortie, valeur} dans Ingescape, le timestamp étant optionnel.
En complément, de façon similaire à Topics, la passerelle propose des services permettant de bénéficier de l’historisation de Kafka. Nous aboutissons donc à une interopérabilité complète entre les deux technologies.
Synthèse de la comparaison entre Apache Kafka et Ingescape
Les fonctionnalités clés proposées par Apache Kafka sont facilement reproductibles dans Ingescape. Ingescape propose davantage de souplesse et de choix de topologie et d’architecture pour s’adapter à davantage de situations à prendre en compte. Les architectures portées par Ingescape, notamment via le Cloud et Internet permettent d’absorber des flux de données de taille similaire à ceux de Kafka, voire même supérieurs pour des agents fonctionnant sur la même machine ou sur le même réseau local grâce à l’absence de broker.
L’historisation et la mémoire immédiate en tant que services et non comme éléments obligatoirement à gérer ou configurer, confèrent à Ingescape un avantage quant aux tailles et complexités minimales d’infrastructures nécessaires à leur fonctionnement. Dans Ingescape, Topics est un simple agent qui peut être exécuté sur n’importe quelle plateforme, même a posteriori de sa mise en place, avec ou sans base de données pour l’historisation qui reste facultative.
Pour les lecteurs avancés, nous donnons ici des avantages complémentaires d’Ingescape qui mériteraient des articles à part entière :
- Outre les brokers, Kafka utilise aussi la solution Zookeeper pour la mise en relation entre producteurs/consommateurs et brokers, en gérant également les services de redondance et de direction de flux à la volée, ainsi que les groupes de serveurs (clusters) et les groupes de consommateurs. Zookeeper est une solution complexe souvent décriée par sa difficulté d’utilisation et son approche paradoxale qui impose une structure centralisée à un système dît de « coordination distribuée ».
- Les interfaces de programmation (API) de Kafka présentent une quantité très élevée (plusieurs milliers) d’objets et de fonctions alors qu’Ingescape, qui fournit un service équivalent, voire supérieur, se contente de 60 fonctions en tout. Kafka, même dans ses surcouches dans des langages de script et par la nécessité de programmer et gérer les brokers, réclame des semaines de pratique pour une maitrise correcte, contre quelques heures seulement avec Ingescape.
- L’implémentation structurelle de Kafka en Java éloigne les brokers de toute recherche de performance et d’optimisation alors que l’approche brokerless d’Ingescape et son implémentation native en C, utilisant les couches réseau de ZeroMQ, reconnues comme étant les plus rapides, offrent des performances au sommet de l’État de l’Art. Il est d’ailleurs impressionnant de voir comment la communauté ZeroMQ, à laquelle nous contribuons, a réalisé en quelques jours un clone fonctionnel de Kafka appelé Dafka qui en reprend les principes de topologie et les fonctionnalités avec des niveaux de performance déjà très supérieurs, au-dessus d’infrastructures beaucoup plus légères et performantes.
- La communauté Kafka déploie des efforts très importants pour connecter des bases de données, gérer les notions de streams, etc. Tout ceci est fait dans le but de ramener le monde extérieur dans le monde Kafka, justifié par la lourdeur intrinsèque de ses infrastructures. A l’opposé, Ingescape maintient une empreinte très faible et permet avec une rapidité remarquable pour intégrer des logiciels tiers, existants ou nouveaux, dans des plateformes logicielles hétérogènes. Le bénéfice obtenu est de pouvoir toujours choisir les meilleures technologies pour les autres tâches que la communication elle-même : connexions avec des bases de données, sérialisation et structuration des données, transformation et fusion de données, balance de charge intelligente, passerelles avec code auto-généré, etc.
RabbitMQ – ventilation des flux de données
Tout comme Apache Kafka, RabbitMQ repose sur les concepts de producteur, broker et consommateur et s’adresse à des systèmes à grande échelle. RabbitMQ tire son originalité des éléments suivants :
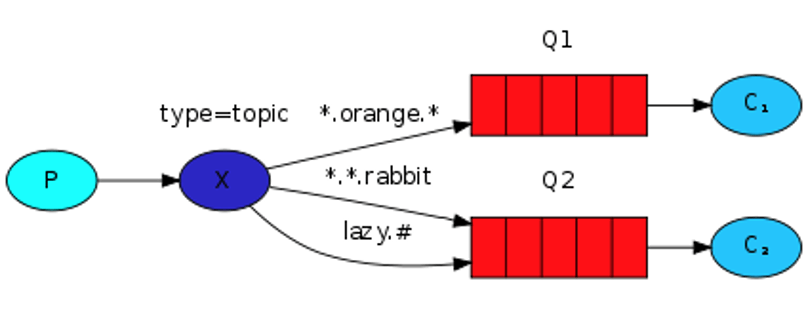
- Support de multiples protocoles dont MQTT, AMQP et STOMP, il se place donc comme un fournisseur de service au-dessus de protocoles de communication établis par ailleurs,
- Un broker RabbitMQ porte des queues qui stockent des messages. Un consommateur s’abonne à une queue donnée. Si plusieurs consommateurs sont abonnés à une même queue, les messages de cette queue seront distribués entre les consommateurs. Ceci fait de RabbitMQ un système de ventilation de messages pour du traitement parallèle piloté par le broker. Ceci alors que Kafka laisse les consommateurs organiser leur consommation, en groupes ou non, en proposant une historisation de ses topics.
- Les producteurs se connectent à un exchange RabbitMQ. Cet exchange se charge ensuite de ventiler les messages vers différentes queues selon des règles d’équité et/ou une analyse des contenus de messages.
Ces trois points sont résumés dans le schéma suivant :
Les comparaisons entre RabbitMQ et Kafka sont fréquentes. Souvent ZeroMQ est associé à ces comparaisons et chacune est mise en avant pour les qualités suivantes :
- Apache Kafka : très hauts débits de distribution des producteurs vers le broker puis avec une latence significative, du broker vers les consommateurs, portés par une infrastructure solide, scalable et résiliente, avec un meilleur débit que RabbitMQ,
- RabbitMQ : polyvalence des protocoles de communication, haute performance dans la distribution en flux tendu des producteurs vers les consommateurs avec un aiguillage efficace par les brokers, meilleure latence que Kafka,
- ZeroMQ : performances et polyvalence supérieures à RabbitMQ et Kafka, latence et débit intrinsèquement meilleurs et mieux contrôlables, pas besoin de broker, multi-langages, multi-OS, avec des fonctionnalités centrées sur les infrastructures et architectures de communication. La relative faiblesse de ZeroMQ est de ne pas bénéficier du même niveau de publicité que ses deux concurrents portés d’un côté par la Fondation Apache et de l’autre par VMWare.
Dans ce cadre, Ingescape a fait le choix fondateur de retenir ZeroMQ comme couche « bas niveau » de communication, lui assurant une performance au-dessus de RabbitMQ et Kafka sans besoin d’infrastructures, et d’étendre ZeroMQ avec un modèle formel mais simple de flux de communication et de services : agents avec entrées, sorties, mapping, et services. La comparaison entre Kafka et Ingescape a montré les avantages en termes de souplesse, sans se priver d’un service d’historisation s’il est nécessaire. Face à RabbitMQ, Ingescape doit proposer un service de ventilation de données que nous présentons ci-après.
Ventilation des flux de données dans Ingescape
Par défaut, lorsqu’une sortie d’un agent Ingescape alimente plusieurs entrées d’autres agents, chacune des entrées concernées reçoit l’ensemble des publications de la sortie de l’agent producteur. Le schéma de distribution massive de données est plus fréquent que celui de la ventilation, c’est à dire d’un partage des données entre plusieurs consommateurs. C’est pourquoi Ingescape le favorise par défaut par le biais des mappings.
Pour assurer une ventilation des données, Ingescape maintient ses concepts d’entrées et de sorties. Il s’agit donc bien de partager les publications d’une sortie d’un agent producteur vers les entrées de plusieurs agents consommateurs, mais en distribuant les données sortantes pour les répartir vers les entrées des consommateurs. Pour cela, nous introduisons la notion de dispatcher qui est un objet associé à une sortie d’un agent et permettant de relayer ce dernier vers des entrées en ventilant les publications de la sortie vers les différentes entrées. Un lien entre un dispatcher et une entrée d’un agent est appelé un dispatch.
Voici la représentation visuelle correspondante :
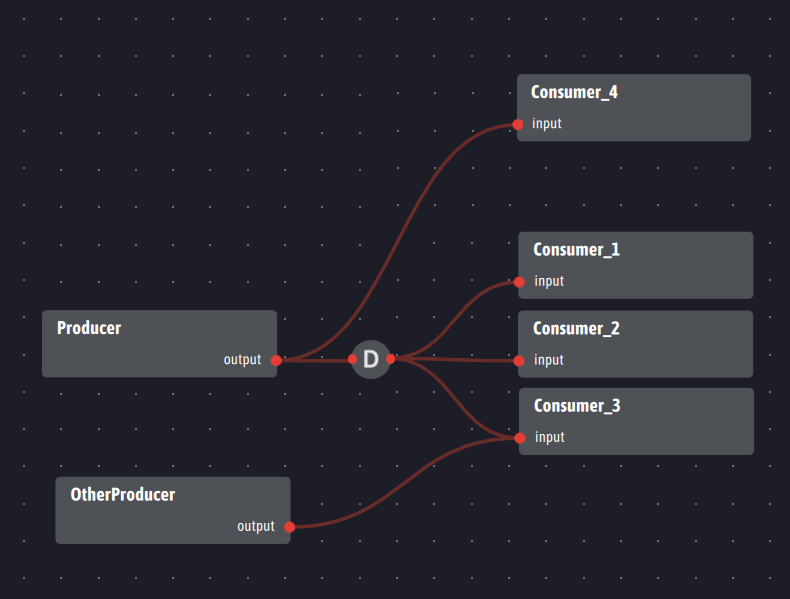
Cette représentation montre la flexibilité très supérieure d’Ingescape en termes de topologie par rapport aux exchanges et queues de RabbitMQ et aux groupes de consommateurs de Kafka. Ingescape facilite la structuration des données qui circulent par la création d’entrées/sorties plutôt que par la création de topics ou de queues sur des brokers. Toute sortie et toute entrée peuvent être utilisées à la fois pour de la diffusion et pour de la ventilation, même simultanément. C’est Ingescape qui assure automatiquement la distribution ou la ventilation selon les mappings et les dispatchers créés. Dans le détail de la topologie ci-dessus :
- La sortie « output » du Producer alimente à la fois un dispatcher vers les entrées « input » des Consumers 1 à 3 et un mapping classique vers le Consumer_4 : Consumer4 recevra toutes les données produites par Producer alors que les Consumer 1 à 3 n’en recevront qu’une partie (33% maximum) selon leur capacité à absorber les données,
- L’entrée « input » de l’agent OtherProducer alimente l’entrée « input » de Consumer 3 de façon classique, en complément du dispatcher attaché au Producer : cette entrée traitera conjointement les données émanant de Producer et de OtherProducer indépendamment de leur origine.
Lorsque plusieurs agents distincts consomment les données passant par un même dispatcher, ils déclarent une quantité de « crédits », c’est à dire de nombre de messages qu’ils peuvent recevoir au maximum. Ensuite, au fur et à mesure du traitement des données reçues, les consommateurs envoient de nouveaux crédits au producteur. Ce mécanisme est nommé « régulation de flux » et permet d’optimiser la distribution des messages :
- Un agent ayant épuisé ses crédits ne recevra pas de nouvelles données avant d’avoir envoyé de nouveaux crédits,
- Le fait d’envoyer plus d’un crédit permet de fluidifier les envois en évitant des temps morts entre les fins de traitement et le renvoi de crédit supplémentaire.
Par rapport aux usages habituels de ZeroMQ, un dispatcher Ingescape ne permet pas de connecter plusieurs sorties. C’est à dire qu’il ne permet pas de coordonner plusieurs producteurs vers un ensemble de consommateurs. Même s’il serait techniquement possible pour Ingescape d’utiliser le mécanisme de contrôle de flux entre plusieurs producteurs et consommateurs simultanément, le rapport coût/bénéfice n’est pas favorable à la solution la plus simple, d’autant que le schéma avec un seul producteur et des consommateurs multiples est de loin le plus fréquent. Cette solution consiste simplement à l’introduction d’un agent, pouvant être une instance Topics ou un agent développé spécifiquement, qui regroupe plusieurs producteurs sur sa ou ses entrées et relaie l’information par sa ou ses sorties vers un ou des dispatchers. Dans cette architecture, les producteurs sont traités en fair queueing et les consommateurs le sont à l’aide du contrôle de flux, ce qui nous ramène à la même topologie efficace que RabbitMQ, la flexibilité en plus.
Interopérabilité entre RabbitMQ et Ingescape
Pour publier des informations depuis une plateforme Ingescape vers un exchange RabbitMQ, le principe reste le même que pour Apache Kafka et MQTT : une passerelle Ingescape RabbitMQ expose une ou plusieurs entrées par exchange et se charge de convertir les données arrivant sur ces entrées en message RabbitMQ à destination de l’exchange.
La ventilation des flux de données de RabbitMQ vers des queues et consommateurs fait que toute passerelle Ingescape RabbitMQ se présentant comme un consommateur ne recevra qu’une partie des données émises par la queue, conformément au principe de ventilation. Il apparaît peu pertinent d’utiliser Ingescape pour ne recevoir qu’une partie limitée des informations de la plateforme RabbitMQ correspondante. Il est probable que l’interopérabilité côté consommateur n’aura véritablement du sens que si l’on souhaite déléguer intégralement le traitement d’une ou plusieurs queues dans un écosystème Ingescape. Il faut donc considérer précisément l’architecture de la plateforme RabbitMQ dont on souhaite consommer des données pour traiter les données de façon adaptée. Cependant, d’un point de vue strictement technique une passerelle Ingescape RabbitMQ capable de consommer des données depuis RabbitMQ ne pose aucun problème.
Pour donner davantage de flexibilité par rapport au contexte de RabbitMQ, nous avons séparé la passerelle Ingescape RabbitMQ en deux agents différents : l’un est dédié à l’envoi d’informations depuis Ingescape vers un exchange, l’autre exploite une ou plusieurs queues RabbitMQ pour les exposer sous forme de sorties de l’agent passerelle à destination de la plateforme Ingescape concernée.
Synthèse générale – Ingescape face à MQTT, RabbitMQ et Apache Kafka
Cet article permet de déterminer comment Ingescape permet de prendre en charge des topologies et architectures similaires à celles de MQTT, Apache Kafka et RabbitMQ. Pour la grande majorité des besoins, les propriétés intrinsèques d’Ingescape répondent directement au besoin et permettent de donner le choix aux concepteurs de la topologie de plateforme qui leur correspond le mieux, localement, entre plateformes distantes et vis à vis des clients distants.
L’historisation, caractéristique d’Apache Kafka, est incluse dans Ingescape sous la forme d’un agent Topics dédié fournissant le service et utilisant une base de données adaptée avec Apache Cassandra… ou toute autre technologie adaptée. Ingescape souhaite résoudre dans le futur la problématique de la synchronisation entre les flux en sortie des agents et les requêtes d’historisation afin de proposer une transparence supérieure à Kafka qui réclame lui-aussi du code spécifique à la charge des développeurs. En l’état actuel de son implémentation, avec l’utilisation de l’agent Topics, Ingescape se porte déjà au même niveau que Kafka.
La ventilation de données a réclamé d’introduire dans le formalisme Ingescape le concept de dispatcher qui est complètement porté par la bibliothèque Ingescape et est exploitable visuellement au travers de l’éditeur Ingescape. Le défi que nous avons relevé était de préserver la simplicité des concepts et la capacité de gestion visuelle via l’éditeur Ingescape, sans réclamer de code logiciel dans les agents utilisant le dispatch via la bibliothèque.
Les points majeurs apportés par Ingescape par rapport à MQTT, RabbitMQ et Apache Kafka sont de :
- Ne pas exiger de broker pour mettre en place des systèmes distribués hétérogènes et néanmoins à haute performance,
- Structurer et segmenter l’information au travers d’entrées/sorties plutôt que via des topics, en gagnant en flexibilité et en dynamicité en cours d’exécution, et en proposant des architectures robustes et résilientes,
- Au travers de passerelles, proposer une interopérabilité complète et simple avec ces trois solutions majeures mais aussi d’autres solutions appartenant à la famille nombreuse des bus logiciels,
- Maintenir une description formelle et vérifiable des topologies garantissant des ponts pérennes avec les mondes de l’architecture système, de la génération automatique de code et de la vérification/validation,
- Garantir une ouverture très supérieure à celle d’Apache Kafka et RabbitMQ sur l’intégration de et dans des technologies tierces, y compris sur les technologies de communication et la sécurité des réseaux.
A lire ensuite
Suite à cet article, deux articles complémentaires sont accessibles :