La problématique de l’interopérabilité des systèmes informatiques est apparue en même temps que les premières architectures client/serveur et n’a cessé d’évoluer depuis autour des notions de requêtes et réponses (request/reply), ainsi que d’appels de fonctions à distance (RPC/RMI). Les architectures client/serveur restent d’ailleurs la solution la plus répandue pour faire interopérer des systèmes distribués, même si les limites imposées par cette approche en termes de niveau de couplage des composants d’un système trouvent depuis plus d’une décennie des réponses plus adaptées avec les bus logiciels et les échanges par flux (voir Plateformes Ingescape – Partie 2 – Bus logiciels et flux de données avec Ingescape).
Cet article reprend de façon chronologique et générale les apports et changements successifs autour des communications client/serveur en mettant en avant les enjeux et bonnes propriétés qui ont émergé au fil du temps. Nous présentons ensuite comment Ingescape se positionne vis à vis de cet historique et apporte une solution à la pointe de l’état de l’art, ainsi que des principes d’interopérabilité améliorés autour du request/reply.
Si ce n’est déjà fait, nous recommandons préalablement la lecture de Plateformes Ingescape – Partie 1 – Les architectures distribuées et le cloud avec Ingescape.
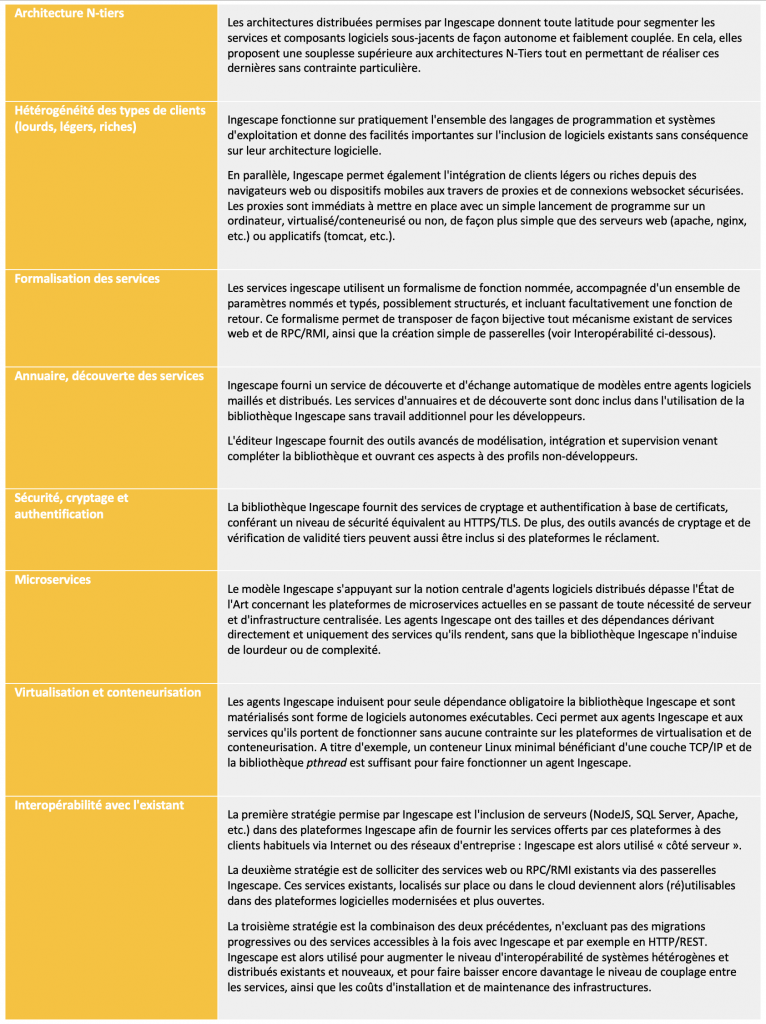
Client/serveur
Le principe de communication client/serveur est demeuré le même depuis ses origines et reste très présent dans les architectures les plus actuelles. Un serveur est en écoute de requêtes provenant de clients. Une requête comporte un ensemble structuré d’informations qui sont traitées par le serveur et peuvent donner lieu à une réponse, également formée de données structurées, du serveur à destination du client ayant émis la requête. Pour formuler une requête, un client doit connaître l’adresse du serveur. Pour répondre à une requête, le serveur doit connaître l’adresse du client. C’est ce que l’on appelle un système fortement couplé où toute évolution du serveur a des répercussions chez les clients qui se doivent d’être conforme au protocole imposé par le serveur.
Au fil du temps, les architectures client/serveur ont permis de faire face aux montées en charge, aux exigences disponibilité et de résilience, et à la nécessaire spécialisation des serveurs quant aux requêtes qu’ils savent traiter et donc à la complexité de leur développement. C’est ainsi que sont apparues les architectures 3-tiers puis N-tiers.
En parallèle, les clients se sont diversifiés selon une catégorisation en clients :
- Lourds : applications indépendantes fonctionnant nativement sur un système d’exploitation,
- Légers et riches : applications fonctionnant dans un navigateur web avec une logique applicative plus ou moins complexe.
Du point de vue de l’interopérabilité, la distinction des types de clients reste induite par les limitations des navigateurs web, notamment en termes de capacités de communication, passant nécessairement par des requêtes HTTP et plus récemment par des websockets. Ceci par opposition aux applications autonomes, capables de communiquer par l’ensemble des autres moyens existants (sockets TCP/IP, IPC, mémoire partagée, etc.). Dans un écosystème donné, tous les types de clients, qu’ils soient lourds ou légers, partagent de fait les mêmes protocoles et les mêmes technologies de communication.
SOA – Service-Oriented Architectures
Avec les architectures N-tiers, les protocoles de communications restaient spécifiques et difficiles à représenter et à implémenter. C’est ainsi que sont apparues les architectures orientées services ou SOA, utilisant toujours les principes de client/serveur et de requêtes/réponses mais permettant une description et une composition des données échangées plus simple, grâce aux formalismes XML puis JSON qualifiés de « formats pivots » entre les entités logicielles concernées.
La notion de « service » au cœur de l’acronyme SOA vient du fait que les serveurs sont masqués derrière une couche de services chargée de les encapsuler et de les abstraire au travers d’un protocole de communication et d’un format pivot dont la définition qualifie un service accessible à des clients. Ceci a pour effet de faire baisser le niveau de couplage entre les clients et les serveurs : les serveurs peuvent évoluer et même se substituer entre eux tant qu’ils implémentent le même service, caractérisé par son protocole de communication et son format pivot d’échange avec les clients. De même, les clients sont indépendants des serveurs et n’ont connaissance que des services qui peuvent alors introduire de la gestion de charge, de la tolérance aux pannes, etc. pour orchestrer différents serveurs.
Concrètement, pour les développeurs de serveurs, services et clients, les SOA se sont démocratisées avec le protocole HTTP au-dessus duquel se sont greffées les architectures SOAP et REST et les formats pivots XML et JSON.
Avec cette approche très ouverte, les SOA peuvent rapidement générer une quantité importante de services, posant deux problèmes : leur découverte par les clients et leur hébergement, associé aux tâches d’administration. Nous abordons ces deux problèmes en suivant.
ESB – Enterprise Service Bus
La découverte des services est généralement assurée par un annuaire – qui est lui-même un service – que les clients et les serveurs consultent pour obtenir les adresses et les formats pivots à utiliser. Les serveurs eux-mêmes peuvent s’appuyer sur des services tiers et sont à ce titre aussi des clients. Un ensemble de services accessibles entre eux et couplés à un annuaire est appelé un bus de services d’entreprise ou ESB. Ce terme désigne en fait une organisation d’un ensemble de serveurs encapsulés dans des services et indexés afin de faciliter leur utilisation par des développeurs et utilisateurs d’applications clients de tous formats (lourds, légers, riches).
La sécurité, le cryptage et l’authentification (ou gestion de l’identité, en particulier le Single Sign-On ou SSO) sont des services transverses faisant partie des ESB.
Dans l’acronyme ESB, le terme de « bus » est utilisé pour désigner le fait que les services et les clients sont utilisables via un adressage indépendant des localisations physiques des ordinateurs sous-jacents. Certaines personnes jugent cette appellation imprécise dans la mesure où les bus désignent généralement des principes d’architecture mettant en jeu la notion d’abonnement.
Microservices, virtualisation, conteneurisation et cloud
L’hébergement des services était historiquement réalisé sur des ordinateurs indépendants, physiquement connectés à un réseau local. L’avènement des technologies de virtualisation (machines virtuelles) puis de conteneurisation – incluant l’emblématique technologie Docker – ont permis d’augmenter significativement la flexibilité des modalités d’hébergement en libérant complètement la correspondance entre serveurs/services et ordinateurs physiques.
Cette flexibilité accrue, combinée à la spécialisation des traitements de données, a également permis de diminuer la taille des services, ainsi que leur capacité à devenir plus génériques et réutilisables. C’est ainsi que l’on parle de microservices pouvant être mis en jeu dans un système avec des mécanismes de virtualisation/conteneurisation (vmware, docker, etc.) et les systèmes de gestion qui les accompagnent (kubernetes, etc.). Ces micro-services peuvent fonctionner sur des hébergements locaux ou dans le Cloud, c’est à dire sur des infrastructures délocalisées et accessibles à distance.
Remote Procedure Calls et Remote Method Invocations – RPC et RMI
La conception de requête et réponse (ou request/reply) est caractéristique de l’architecture client/serveur et de ses descendantes. Cependant, la capacité à transmettre une commande, accompagnée ou non de données, d’un programme à un autre par le biais d’un moyen de communication (TCP/IP, IPC, etc.) est aussi un concept de développement logiciel décliné selon d’autres principes regroupés autour des Remote Procedure Call (RPC) ou Remote Method Invocation (RMI) en contexte orienté-objet.
De nombreuses solutions de RPC/RMI existent et se sont succédées dans différents langages de programmation et frameworks de programmation (Qt Remote Objects, XML-RPC, D-Bus, CORBA, etc.). Tous partagent les notions de commandes accompagnées de paramètres, héritées des appels de fonctions ou méthodes d’objets de la programmation informatique classique. Ces commandes peuvent être synchrones : le client émettant la commande est bloqué jusqu’à recevoir la réponse du serveur. Mais la plupart des solutions RPC/RMI d’aujourd’hui sont devenues asynchrones, laissant la synchronicité à des cas spécifiques qui le justifient encore.
Ingescape pour les services et le request/reply
Fondamentalement, les différentes formes de request/replies et les RPC/RMI reposent exactement sur le même principe d’appel de fonction à distance avec ou sans paramètres. Les enjeux associés sont eux aussi identiques :
- Pour un service donné, formalisation des « fonctions » et de leurs paramètres, partagés entre clients et serveur,
- Les formalismes sont nombreux incluant notamment SOAP, WSDL, CORBA, etc. Ils créent des opportunités de génération automatique de code, vérification des formalismes, de versionnement des services, etc.
- Adressage d’un service pour une requête, et réciproquement adressage d’un client en cas de réponse,
- Accès aux services depuis des clients lourds et légers, sur des réseaux locaux et/ou depuis l’Internet ou des réseaux distants, possiblement sécurisés.
Formalisation des « fonctions »
Dans le monde du Cloud actuel, les solutions HTTP/REST/JSON sont les plus populaires pour le request/reply. Dans ce contexte « web », le développement d’un service, bien que largement outillé et utilisant des descriptions de haut niveau, reste un processus qui prend plusieurs heures à plusieurs jours entre la conception et la mise en service. La cause principale est le nombre de couches logicielles et donc la quantité de code (tiers ou spécifique) impliquée pour assurer le fonctionnement permettant à un client d’appeler un service, à un service de traiter la requête et générer la réponse, et au client de traiter la réponse reçue.
Les solutions de RPC/RMI sont généralement plus directes à mettre en œuvre, se rapprochant d’appels de fonctions ou de méthodes d’objet depuis un client vers le service concerné puis, dans le cas le plus fréquent où la réponse est reçue de façon asynchrone, par l’appel d’une fonction côté client, souvent appelée callback, pour traiter la réponse reçue. Ceci s’apparente aux principes de base de la programmation réactive qui sont simples à comprendre pour les développeurs.
Un agent Ingescape expose ses services, appelées Ingescape services, à la manière de fonctions nommées, ayant un certain nombre de paramètres (zéro ou plus), chaque paramètre étant nommé et typé, selon les types habituels proposés par Ingescape (bool, int, float, string, data).
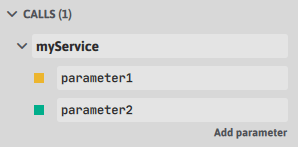
Avec Ingescape, un service myService ayant un premier paramètre parameter1 de type entier et un second paramètre parameter2 de type chaine de caractères, exposé par un agent myAgent peut être appelé depuis un autre agent selon une logique myAgent.myService(12, « my string »), c’est à dire comme l’appel d’une méthode sur un objet avec les paramètres appropriés.
Les services d’un agent sont modélisés dans la définition de ce dernier. Voici la forme que prend notre exemple ci-dessus dans le modèle Ingescape :
{
"definition": {
"name": "myAgent",
"version": "1.0",
"services": [
{
"name": "myService",
"arguments": [
{
"name": "parameter1",
"type": "INTEGER"
},
{
"name": "parameter2",
"type": "STRING"
}
]
}
]
}
}Langage du code : JSON / JSON avec commentaires (json)Et voici la forme visuelle et éditable que cela prend dans l’éditeur Ingescape:
Si un besoin complémentaire de structuration est nécessaire, le modèle proposé peut être complété par des formalismes tiers. Par exemple, un paramètre de type « chaîne de caractères » peut être défini comme étant du JSON ou du XML auquel est associé un schéma particulier (DTD, XSD, etc.). De même, un paramètre de type « data », c’est à dire de la donnée binaire, peut être défini comme une donnée structurée sérialisée, associée à un formalisme de sérialisation tel que Protocol Buffers avec un fichier « .proto » et un message particuliers. De cette manière, il n’y a pas de limite à la complexité des données qui peuvent être échangées au travers des services.
Selon le langage informatique dans lequel l’agent est développé, le service est directement mis en correspondance avec une fonction de traitement reprenant directement les paramètres du service, ainsi que l’identité du client appelant le service (ou du serveur ayant généré la réponse). De cette manière, le développeur a directement la possibilité de répondre à une requête, sans devoir se plonger dans différentes couches logicielles.
En complément, les services échangés avec Ingescape intègrent aussi une notion de token qui permet de faire un suivi individuel des différentes requêtes et réponses, de sorte à ce qu’un client qui émet des requêtes multiples sache toujours à laquelle de ses requêtes correspond la réponse reçue.
Les services Ingescape offrent donc les mêmes possibilités conceptuelles et formelles que les services web de type HTTP REST/SOAP XML/JSON et que le monde des RPC/RMI, avec un niveau de complexité nettement plus simple, équivalent à celui de la déclaration d’une fonction dans un simple programme informatique. Si l’on ajoute le fait qu’il est par exemple très simple de créer un agent « serveur » utilisant la technologie NodeJS et des agents « clients » fonctionnant en Javascript dans un navigateur web, Ingescape peut directement être évalué et comparé aux technologies habituelles HTTPS/REST/JSON pour concrètement mesurer les apports en termes d’efficacité, de contrôle et de supervision des requêtes/réponses.
Adressage et accès aux services
Les solutions HTTP/REST/JSON réclament la mise en place d’un système d’adressage et de résolution de noms liés au protocole HTTP. Les systèmes RPC/RMI reposent généralement sur des solutions similaires avec un annuaire central.
A l’opposé, Ingescape repose sur un réseau maillé complètement décentralisé (voir l’article Plateformes Ingescape – Partie 1 – Les architectures distribuées et le cloud avec Ingescape). Pour utiliser un service, il suffit de connaître le nom de l’agent qui le porte, sans complexité d’adressage. La disponibilité d’un agent et des services qu’il porte est activement détectée par les autres agents, tout comme une disparition, pour cause d’arrêt volontaire ou de panne : chaque agent sait en temps-réel quels sont les agents présents. Ingescape apporte donc une capacité de résilience et d’adaptation dynamique naturelle, difficile à mettre en place sur les systèmes client/serveur classiques.
Plusieurs clones d’un agent peuvent porter le même service et se coordonner pour proposer une redondance à chaud et un agent de façade peut également servir d’intermédiaire à une équipe d’agents « de calcul » afin de réaliser un load balancing sur une ou plusieurs machines virtuelles ou physiques, voire sur des infrastructures différentes.
Les capacités de supervision des plateformes Ingescape donnent une capacité unique à détecter des variations ou des incohérences dans les descriptions de service des agents via leur définition qui est elle-même versionnée. Ingescape apporte donc un contrôle de cohérence global à l’échelle d’une plateforme, ce contrôle étant actualisé en temps réel lors de toute arrivée et de tout départ d’agent, permettant une réactivité et une alerte immédiate en cas d’incohérence ou de perte de service.
Enfin, les solutions HTTP/REST/JSON proposent des performances de communication le plus souvent faibles, inhérentes au HTTP/TCP/IP, avec des latences élevées et des canaux de communication prédéterminés. L’aspect « multi-transports » et les performances brutes d’Ingescape permettent d’atteindre des performances très supérieures, uniquement dépendantes des localisations physiques d’un client et d’un serveur et à la bande passante accessible entre eux. Avec Ingescape, les communications n’étant pas limitées au TCP/IP mais pouvant bénéficier de canaux beaucoup plus rapides si les services sont localisés sur le même matériel, les services Ingescape sont aussi adaptés à du traitement à très haute performance sans modification du code existant pour le service développé.
Interopérabilité entre Ingescape et les autres types de solutions
Contrairement à toutes les technologies tierces citées dans cet article, Ingescape propose une interopérabilité naturelle avec les solutions HTTP/REST/JSON et RPC/RIM. Sur la base de formalismes tels que le WSDL or Swagger/OpenAPI, et en utilisant les technologies de génération automatique de code accompagnant Ingescape, il est particulièrement facile de créer des passerelles entre des systèmes existants de type client/serveur HTTP/REST/JSON ou RPC et des plateformes Ingescape.
Voici les schémas d’interopérabilité facilités par Ingescape vis à vis de l’approche client/serveur :
- Passerelle
- Un service web existant sur un serveur donné peut être encapsulé par un agent Ingescape dédié qui traduit chaque service en un service avec les paramètres correspondants. L’agent formule les requêtes vers le serveur en format HTTP/REST/JSON et retransmet les réponses du serveur directement vers l’agent ayant sollicité un service donné. Cette approche de type passerelle permet une mise en œuvre très simple de services web existants vers une plateforme Ingescape locale ou distante et est également valide pour des solutions de type RPC/RMI.
- Hybridation d’un serveur existant
- De façon plus intégrée, un serveur peut inclure une couche Ingescape en parallèle d’une couche HTTP/REST/JSON ou RPC/RMI existante. De cette manière, le serveur devient un agent à part entière et peut offrir des performances de communication très supérieures au HTTP/REST/JSON sans renoncer à ces dernières. D’expérience, la mise en place de ce type de stratégies pour des serveurs Microsoft SQL Server, NodeJS, etc. est très simple à mettre en œuvre et impose des contraintes négligeables sur l’architecture et la charge du serveur existant.
- Agent Ingescape comme serveur HTTP/REST/JSON ou RPC/RMI
- Un service porté par un agent sous forme de service peut également être relayé via une passerelle ou directement par une prise en charge HTTP/REST/JSON ou RPC/RMI par l’agent lui-même qui devient alors aussi un serveur.
Ces trois approchent montrent bien la volonté et la flexibilité qu’apporte Ingescape quant au décloisonnement des données et des services en contexte client/serveur.
Synthèse
En guise de synthèse, nous proposons un tableau présentant les principes majeurs attendus pour les solutions client/serveur, request/reply et (micro)services, et comment Ingescape se positionne pour chacun d’entre eux.